
# Computer_Architecture
# Understanding the Computer system
# Computer Components
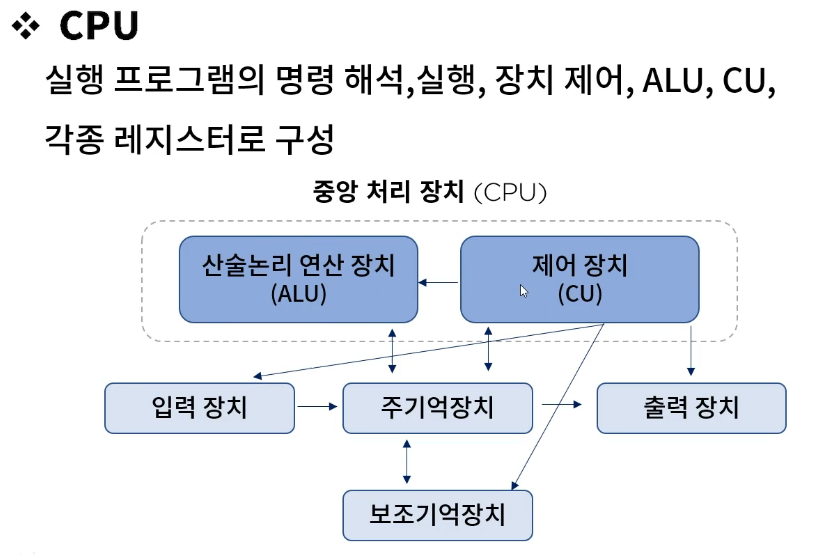
CPU
- CPU/MPU (MPU는 CPU를 여러개 묶어놓음)

- 요즘은 Integrated Circuit인 마더보드에 탑재돼있다.
- MPU(Micro Processor Unit)
- CPU를 LSI(고밀도 집적회로)화 한 통합장치
- CISC : Complex Instruction Set Computer. 기본 기능들은 반복적이고 패턴이 일정하므로 이걸 소프트웨어로 안하고 HW로 하겠다는 MPU.
- RISC : Reduced Instruction Set Computer. 반대 개념.
- Bit Slice MPU : 두 종류를 적절히 쪼개서 조합시킨다.
- 사물 인터넷 디바이스 HW -
- 아두이노 : 2005년 이탈리아에서 탄생. 오픈소스 HW 플랫폼.

- Raspberry Pi : 영국에서 만듬. 훨씬 더 컴퓨터
Peripheral
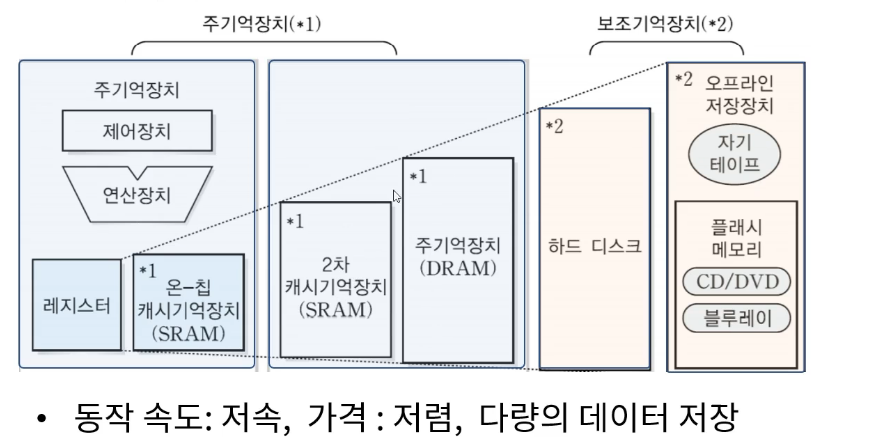
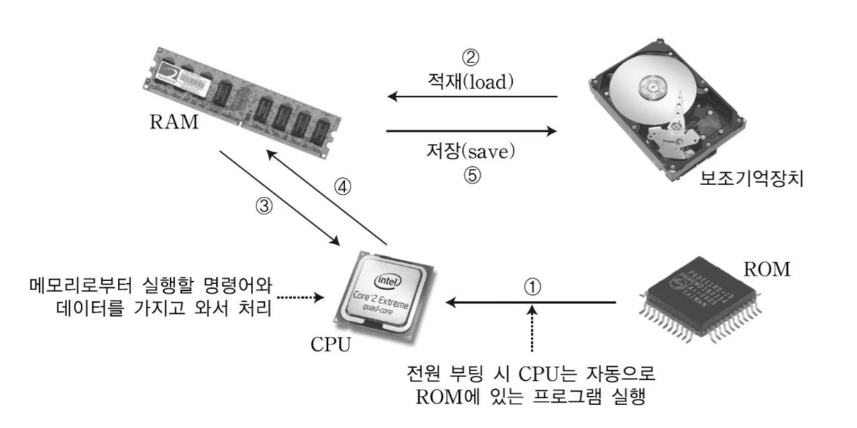
Memory
- RAM : 칠판처럼 리프레쉬. 작업대.
- ROM : Read Only Memory. 운영체제 부팅시 사용. 지워지지 않는다.
Auxiliary memory device
IO device
# Data Expression
# Data Types
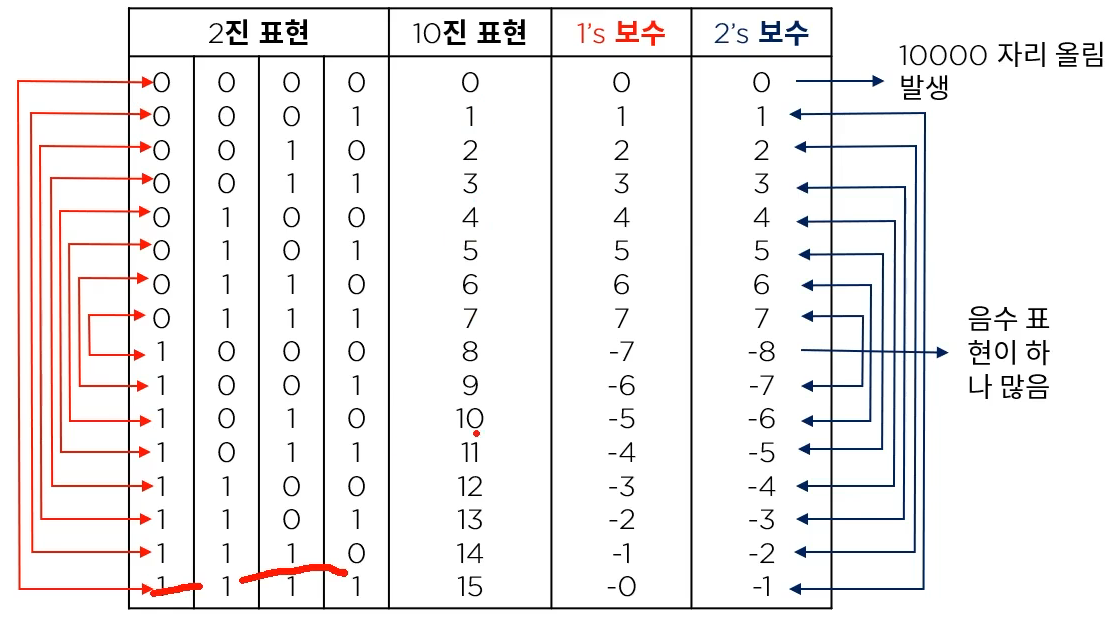
# Complement : 보수
- 최대값(해당비트에서 가장 큰 표현형)을 형성하는데 서로 보완 관계에 있으면 1의 보수라고 한다.
- Modulus를 형성하는데 보완관계에 있으면 2의 보수라고 한다.
- example
- 3의 1의보수는 6, 2의보수는 7
- 18의 1의 보수는 81, 2의 보수는 82
- 2진 보수
- 1의 보수 : 자신의 수를 반대로 바꾸낟.
- 2의 보수 : 1의 보수에 +1
# 정수
부호와 절대치를 따로 보관한다.
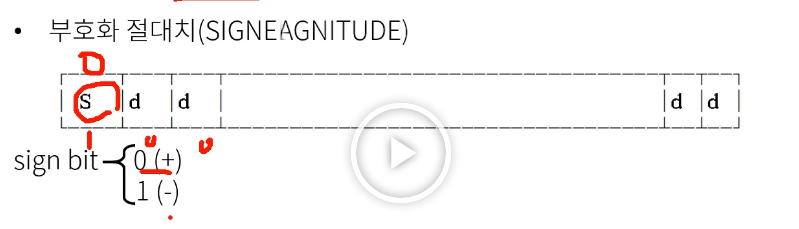
- 문제점 : +0과 -0이 두개 존재한다.
해결 : 2진 보수로 정수를 표현한다.
- 2진 보수의 2의 보수를 취하면 0의 2의 보수는 그대로 0이되게 할 수 있다.
- ex : 0000의 2진 보수의 2의 보수는 10000. 그러나 앞의 비트를 날려서 0000이 된다.
- 10진수 표기(Unpacked Decimal)
- 연산은 할 수 없고 입출력용으로만 사용
- 1byte를 이용해 한 숫자 표현가능.
- 1byte = 8 bit = 두개의 hexa
- 첫 hexa는 무조건 F(1111) 두번째 hexa로 숫자 표현.
- 숫자의 마지막 숫자앞에만 F대신에 S
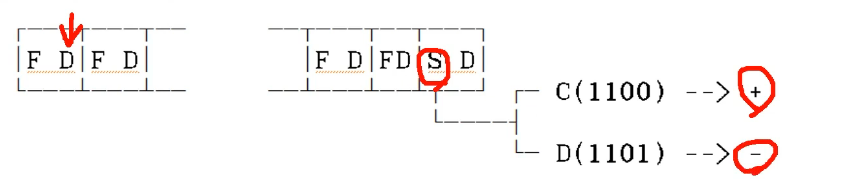
- 10진수 연산(Packed Decimal)
- F값 다 제거하고 S는 제일 뒤로 .
- 연산에 이용되고 입출력은 불가능하다.
# 실수

# BCD(Binary Coded Decimal Code)
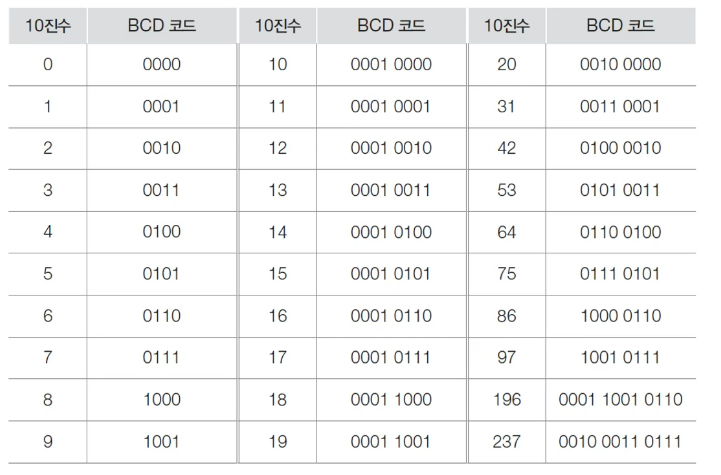
- 입출력용이여서 연사이 안된다.
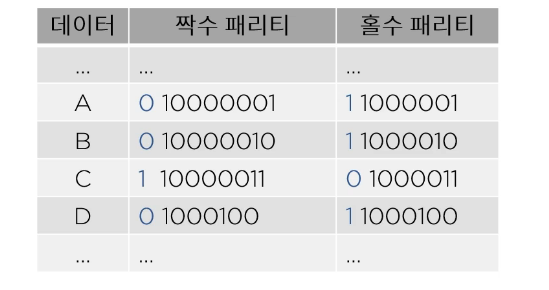
# 에러 검출 코드
패리티 비트
해밍 비트
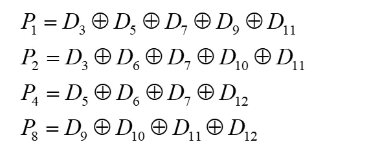
뺄셈을 보수의 덧셈으로 계산하는 법

# ALU and Data Expression
# 논리 게이트
정해진 논리 함수를 수행하여 연산결과와 동일 값을 출력하는 하드웨어
스위칭 이론
- 1938년 C.E. Shannon 과 Bool에 의해서 만들어짐.
논리연산 기본
AND
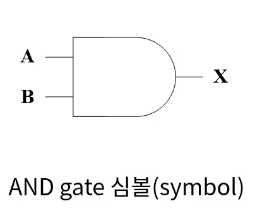
OR
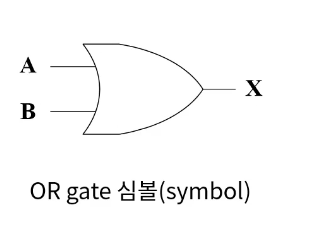
NOT
XOR
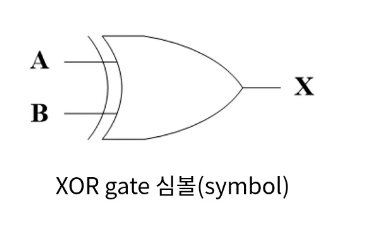
반가산기
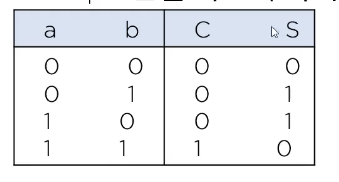
- 진리표를 보면 AND와 XOR을 쓰면 반가산기를 만들 수 있다.
전가산기
부울대수(Boolean Algebra)
1854년 영국의 G.Boole이 만들었다.
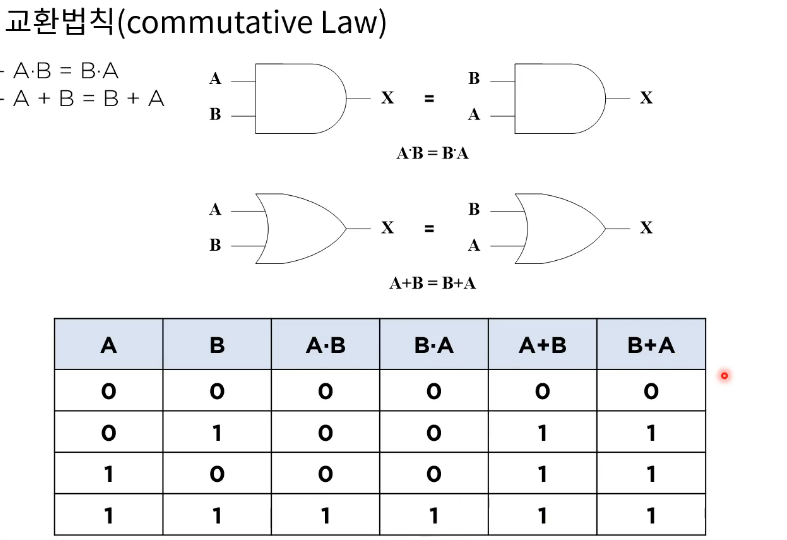
교환법칙(commutative)
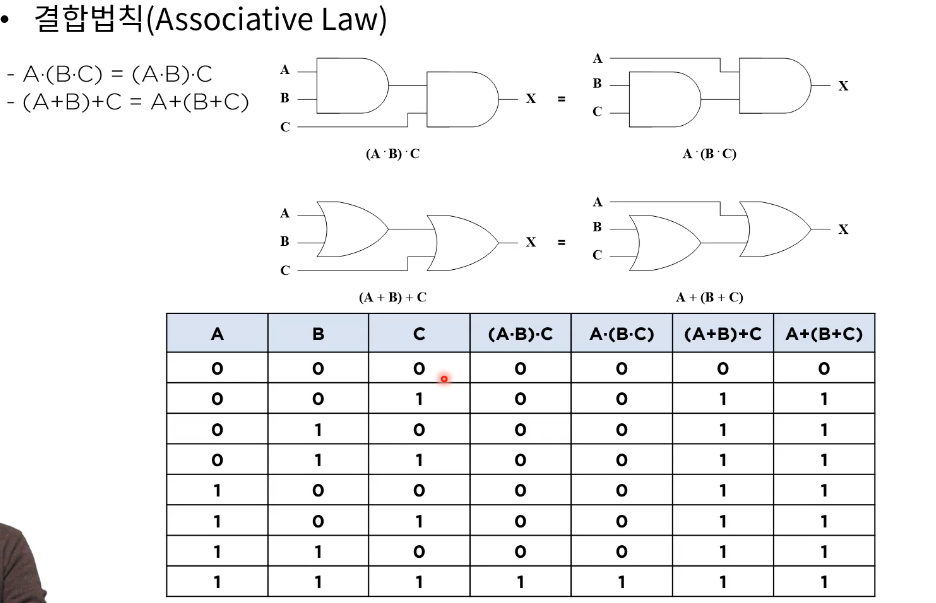
결합법칙(associative)
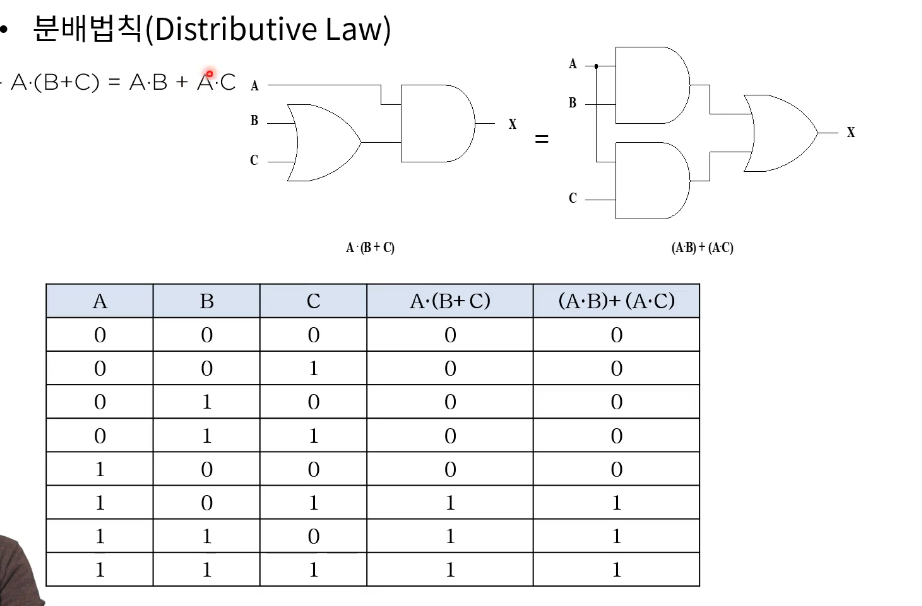
분배법칙(distributive)
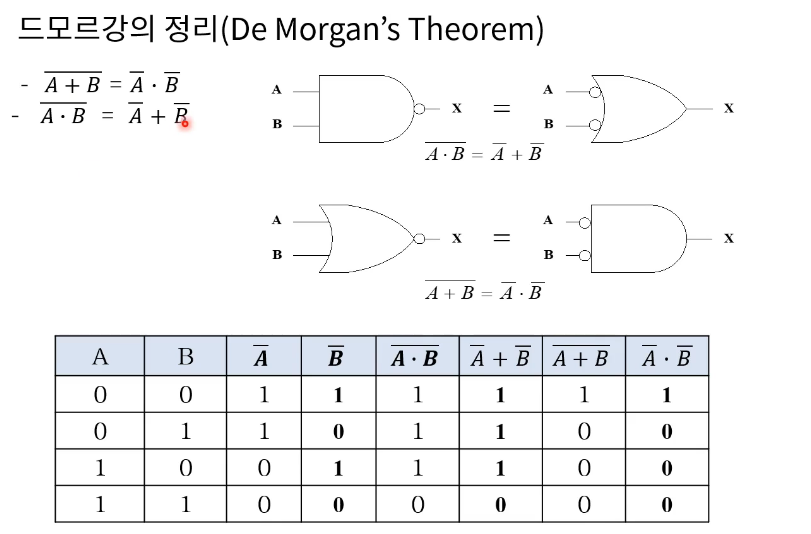
드모르간의 정리(De Morgan)
Example
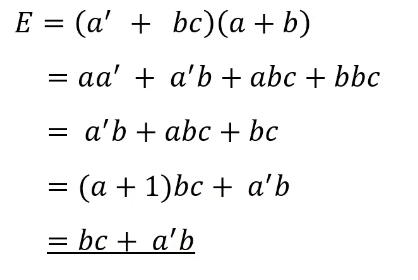
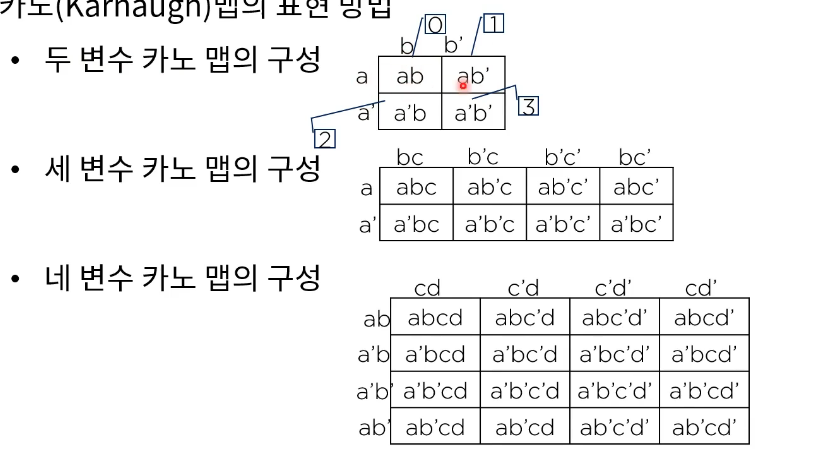
카노 맵 ( Karnaugh) : map은 부울 함수를 바로 간소화 가능.
표현방법
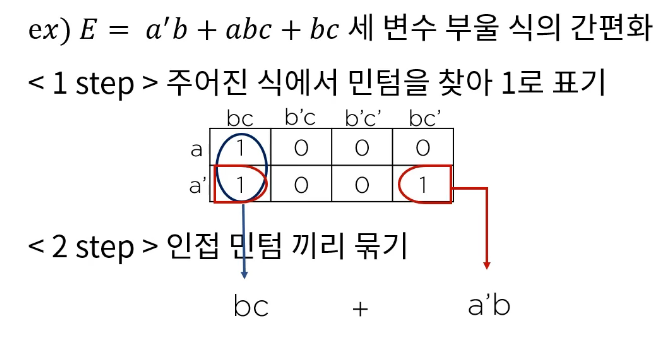
# 조합 & 기억 논리 회로
- 조합논리 회로
- 논리게이트의 집합이며 입력에 의해 조합함수 출력이 결정.
- 설계 절차
- 문제 제시
- 입출력 변수에 문자 기호 붙인다
- 입출력 관계 정의 진리표 유도
- 간소화된 부울 함수 얻는다
- 논리도 작성
- 기억회로
- 순차회로
- 조합회로에 기억회로(flip flop)이 합해져있다.
# CPU
# 내부 구조와 레지스터
CPU의 구성요소
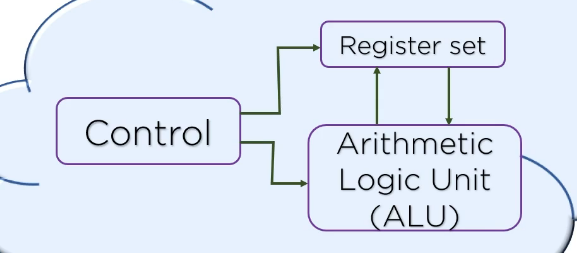
Register Set : 명령어 실행에 필요한 데이터를 일정 시간 보관
Control Unit : RS간 정본전성, ALU에게 지시
ALU : 명령어 실행 위한 마이크로 연산 수행
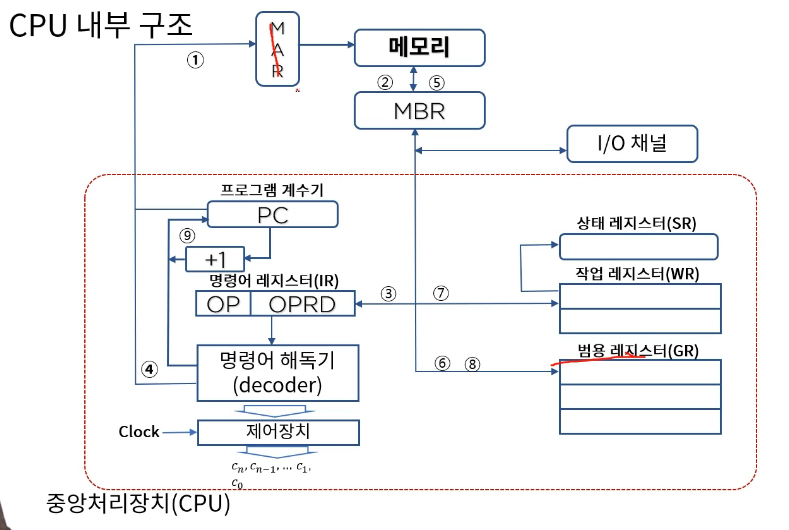

레지스터들의 명칭과 기능
Program Counter : 다음 수행될 명령어가 있는 주기억장치의 주소를 기억하고 있는 레지스터
Instruction Register : PC가 지정하는 주소에 기억되어 있는 명령어를 임시 기억.
Instruction Decoder : IR에 있는 명령어를 해석하는 논리회로
Control Unit : ID가 보낸 신호에 따라 명령어 실행
general purpose register : 작업 레지스터에 보낼 DATA를 임시저장
working register : ALU에 보낼 자료와 결과를 저장
Status Register : CPU상태를 나타냄. (Z:0, S:Sign, V:overflow, C:carry, I:interrupt)
# 명령어와 내부 구조
명령어구성과 실행
Micro operation : 레지스터에 저장된 데이터를 조작(shift, count, clear, load)하는 동작
레지스터 전송
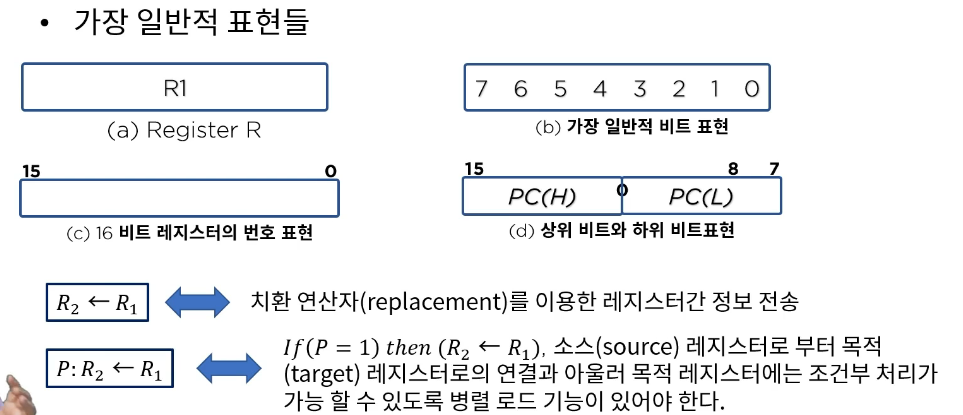
레지스터 전송을 나타내는 각 문장들은 전송을 수행하는 하드웨어가 구성되어 있음을 의미한다.

그러나 디바이스들간 직접연결하면 복잡도가 O(n^2)로 늘어난다
그래서 버스연결(공용선)을 사용하게됐다.
# 마이크로 명령과 ALU
# 마이크로 명령어 집합과 구성
# 마이크로 명령 입출력과 인터럽트
시간 스케일
- 프로세스 : 10 micro sec
- 입출력 : 0.1s = 100,000 micro sec
- 결론적으로 전송시 끝났나 안끝났나 5000번의 플래크 체크 필요 -> 그래서 인터럽트가 필요해진다.
인터럽트
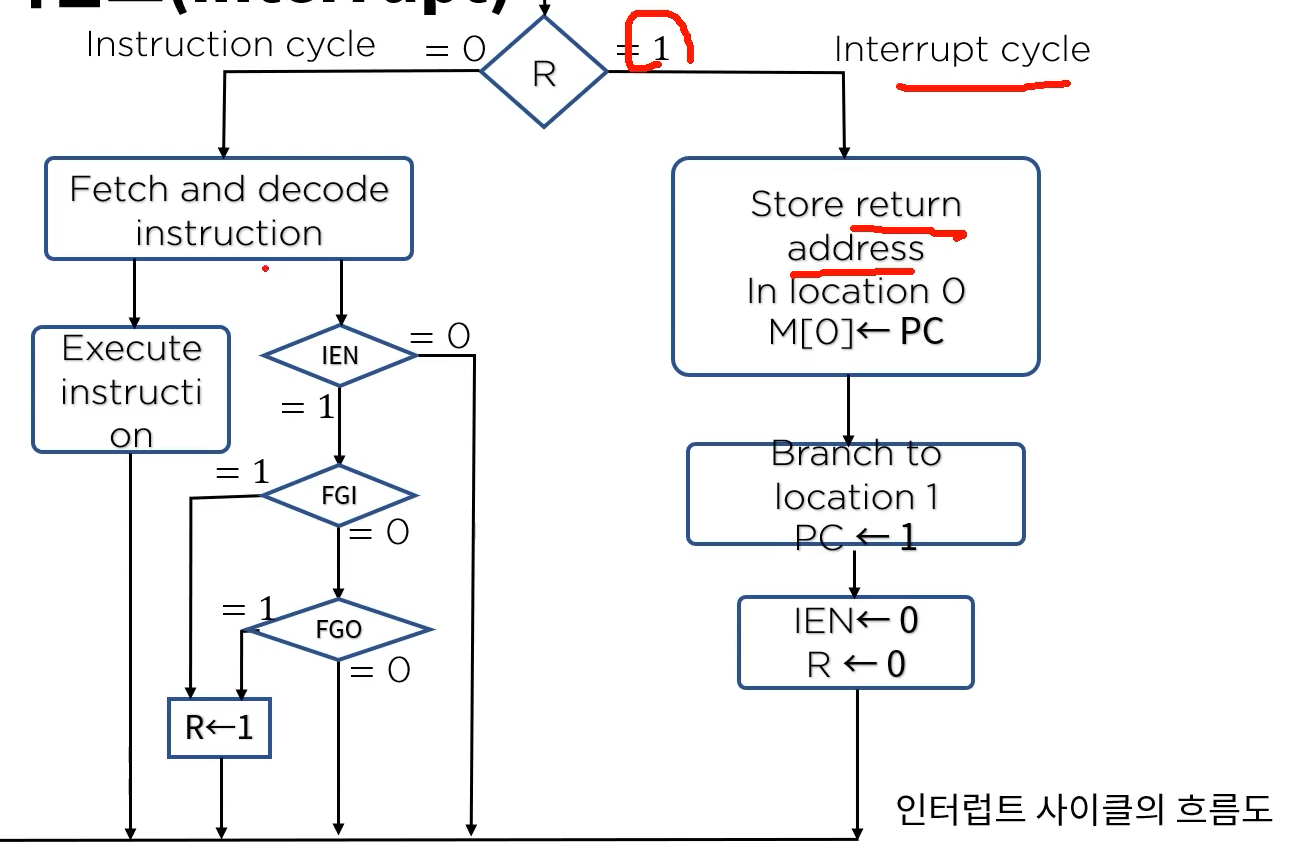
- R이 1이면 인터럽트 발생. 마지막에 R값 초기화
- IEN : Enable
- FGI :
- FGO :
# 컴퓨터 프로그래밍
- 프로그래밍 일반
- HW
- SW
- 시스템 SW
- 운영체제
- job관리
- 스케쥴
- 네트워크
- 입출력
- 언어번역
- 컴파일러
- 어셈블러
- 인터프리터
- 유틸리티
- DBMS
- 백신
- 드라이버 관리
- 운영체제
- 응용 SW
- 어플리케이션
- 모바일 어플
- 시스템 SW
- 기계어
- 어셈블리어
- 컴퓨터 제조 업체마다 다르다.
# 프로그래밍 언어와 실행
- 패러다임의 변화
- 구조적 기법 : 코볼, 포트란
- 객체지향 : C++, 자바
- 컴포넌트
- 분산객체 : 컴포넌트의 클라우드화.
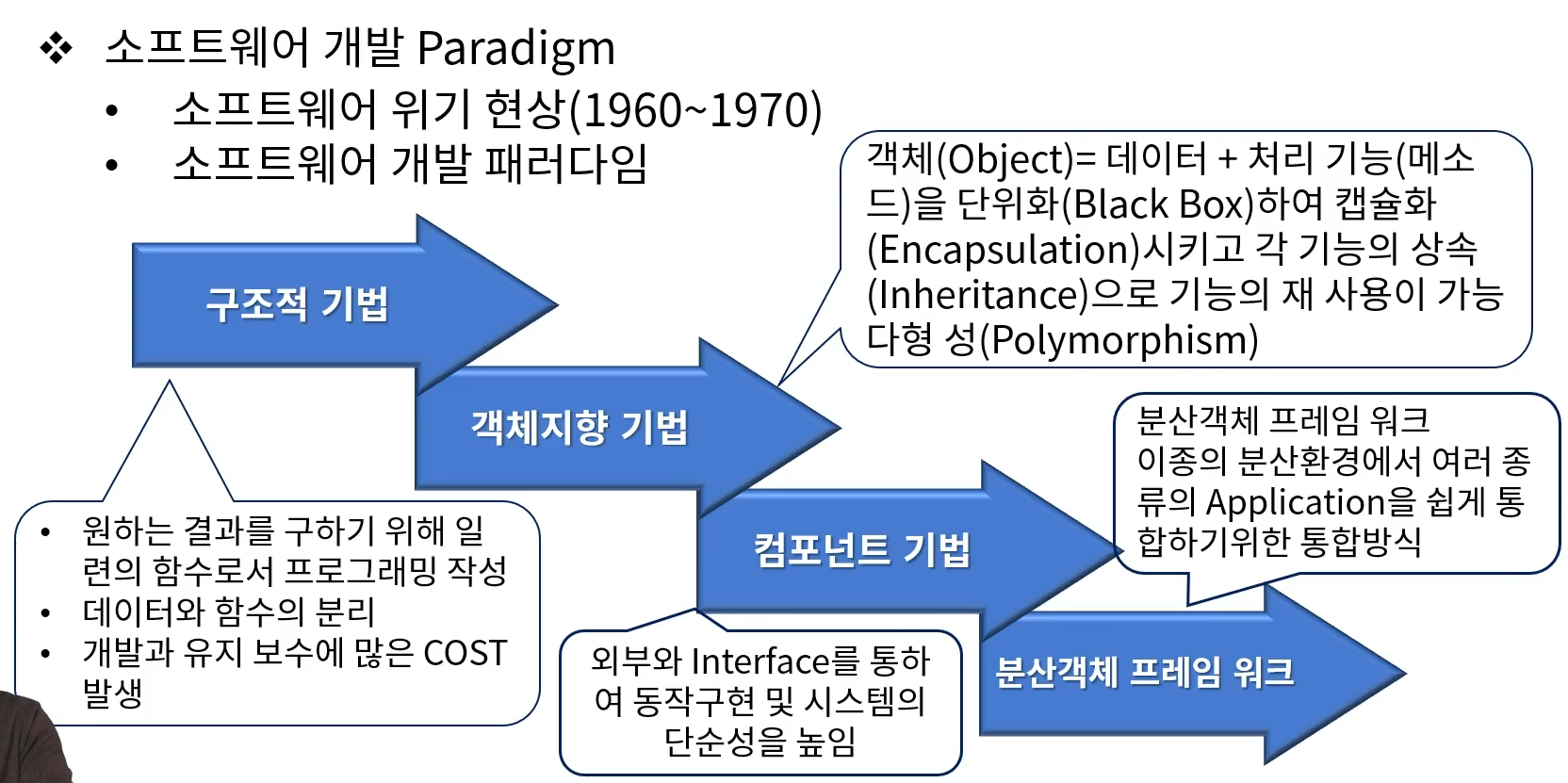
- 네트워크 환경
- 컴퓨터는 통신기계가 되었다.
# 4. Pipeline and Vector
# 병렬 처리와 파이프라인
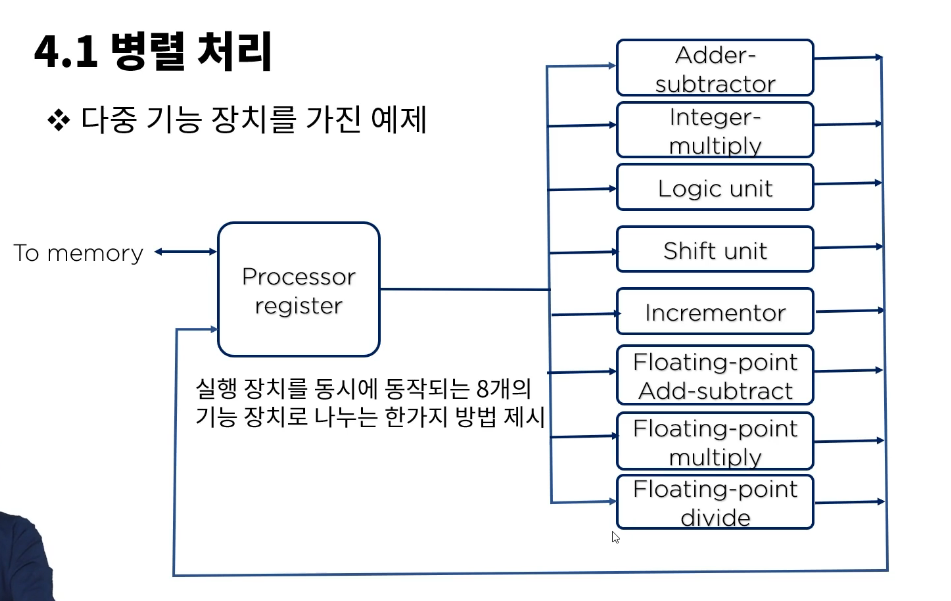
- 로직은 복잡해지지만 발전한계를 뚫기위한 방안으로 제시됨.
# Flynn의 분류방법
동시에 처리되는 명령어와 데이터 항목수에 의해 컴퓨터 시스템 구조를 파악하려는 분류 방법 제안. 외양적 행동 양식을 강조했다. 이 분류에 적합하지 않은 것이 파이프라인이다.
- SISD(Single Instruction Single Data) : 단일 명령어 흐름, 단일 데이터 흐름. 제어-처리-메모리를 가지는 단일 컴퓨터 구조.
- SIMD : 공통 제어장치, 여러개 처리 장치. 동일한 명령어로 다른 데이터에 대해 실행 가능. 모든 프로세서가 메모리에 동시 접근 위해 다중 모듈을 가진 공유 메모리 장치가 필요.
- MISD : 이론적으로만 연구. 양자라면 가능?
- MIMD : 쿼드코어, 듀얼코어가 이런 방식이다.
# 파이프라인

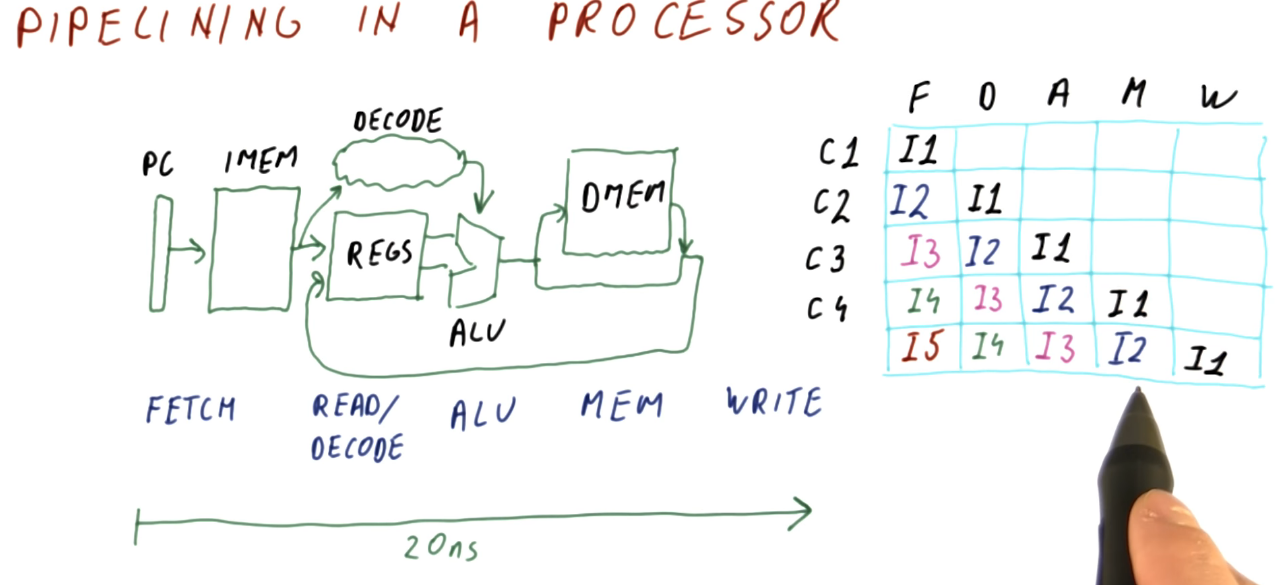
- T1은 네번의 작업을 하면 끝난다.
- 4개의 세그먼트 파이프 라인에서, 6개의 데스크를 수행했다.
- T1을 완료하기 위해 4*t 만큼의 시간이 필요
- 결국 완료를 위해선
- 4*t + (6-1)t = (4+6-1)t 클럭 사이클이 걸린다.
- generalize하면 (k+n-1)t 클럭 사이클.
# 파이프라인 vs 비파이프라인

- n개의 테스크를 k개의 세그먼트로 분리해서 본다면?
- 파이프라인의 이론적 최대 속도 증가율은 세그먼트 수와 같다.
# Pipeline 구조
# 파이프라인의 구현
- 하나의 프로세스를 여러 프로세스로 나눈다.
- 각 세그먼트는 분리된 프로세스를 연산하여 결과를 다음 세그먼트에게 전달해준다.
- 하나의 프로세스를 다양한 연산으로 중복할 수 있는 근간은 세그먼트마다 있는 레지스터다. 왜냐면 중간결과를 저장해야되니까!
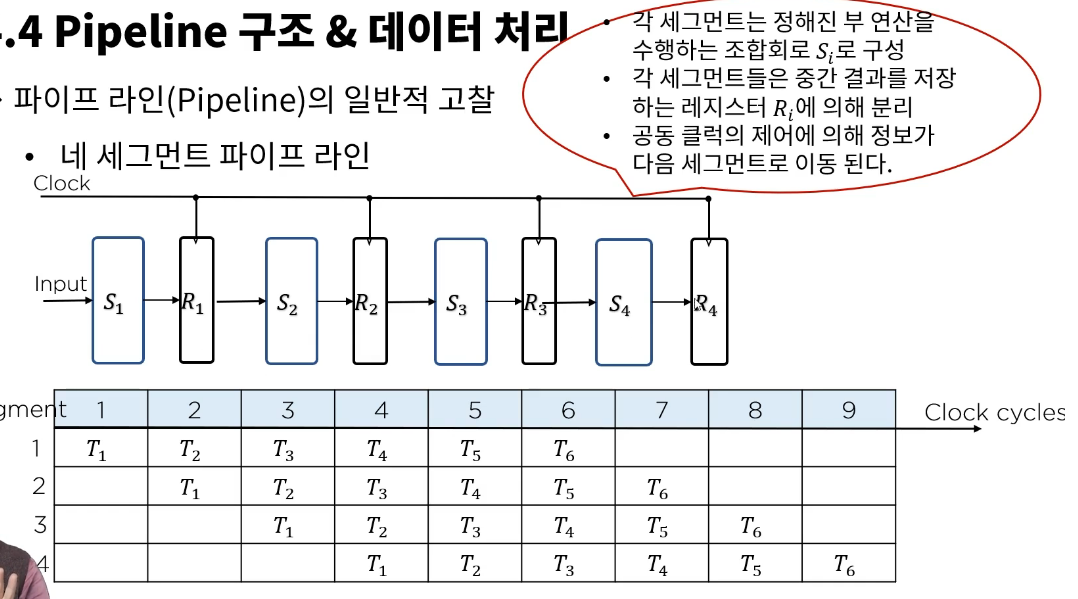
- 업무강도가 세그먼트간에 일정해야한다.

- 이상적으로 보면 속도증가율이 세그먼트수에 근접한다.
# 현실적 병렬적 다중 기능 장치
실제와 이론적 파이프라인의 차이
- 각 세그먼트의 연산속도가 차이가 나고 클럭은 그 중 가장 느린 세그먼트에 싱크를 맞춰야 한다.
병렬적 다중 기능 장치
동일한 명령어를 반복처리해야되는 경우
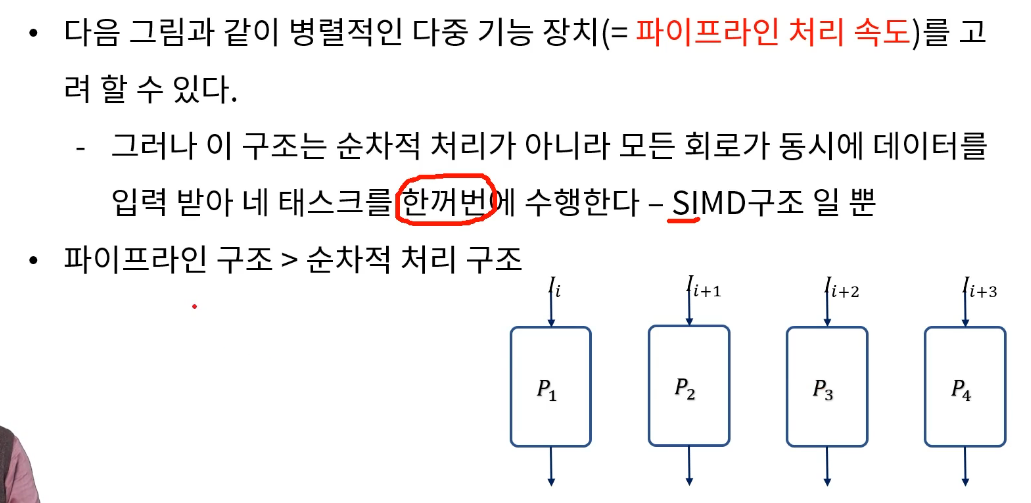
그러나 순차적인 처리는 불가능하다.
파이프라인 적용이 효과적인 경우
- 산술 파이프라인 : 연산 - 곱셈
- 명령어 파이프라인 : fetch - decode - execute
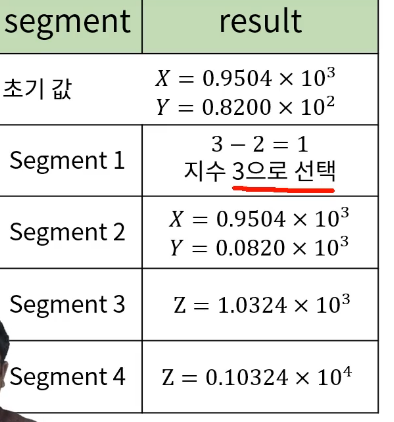
# 산술 파이프 라인
부동 소수점 덧셈과 뺄셈을 위한 파이프 라인
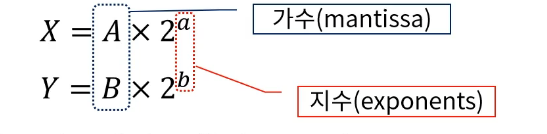
세그먼트 나누는 법
지수의 비교
가수의 정렬
가스의 덧셈 뺄셈
결과 정규화
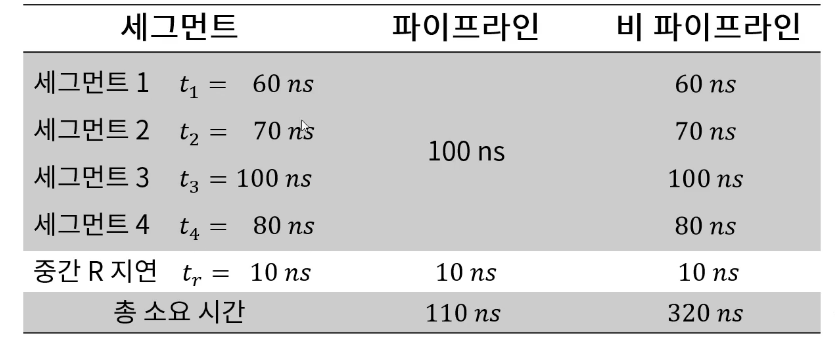
# 명령어 파이프라인
- fetch -decode -exe를 동시에 실행하면서 효율적으로 하는 파이프라인
- 다만 분기가 발생한다면 현재 파이프라인을 다 비워야 한다
- 분기 이후 읽어오는 명령어는 모두 무시해야 한다.
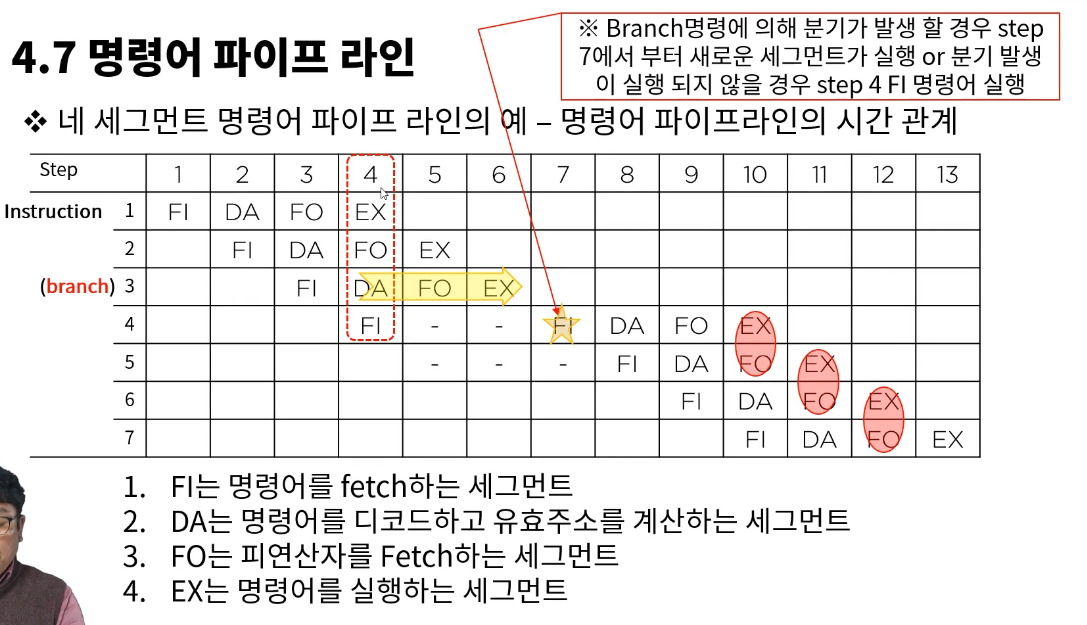
- fetch와 실행 장치 두개의 세그먼트 파이프라인을 만들었다 치자.
- fetch는 que로 구성된 명령어를 fifo로 처리
- 수행시간이 서로 다르면 문제가 된다.
- 동일한 곳에서 fetch를 하면 문제가 발생한다. -> 데드락
# 파이프라인 CPU의 성능 분석
# 파이프라인 분기 예측
파이프라인이 비정상 동작하는 경우
- 자원충돌 : 여러 세그먼트가 메모리 동시 접근 경우. 해결방안은 명령어 메모리와 데이터 메로리를 분리.
- 데이터 의존성 : 이전 명령어 수행결과가 아직 준비되지 않았을 때. 오버플로우 했을 경우에도 발생.
- 분기 곤란(branch difficulty) : 분기 명령어가 PC의 값을 변경할 때
분기 명령어 처리
- 성능 저하의 주 요인
- 해결방안
- 순차적으로 처리될 명령어를 분기의 목표가 되는 명령어와 함께 저장해서 해결
- 분기 목표 버퍼(BTB) : fetch 세그먼트의 associative memory(주소가 아닌 내용으로 검색 가능한 기억장치)로 이전에 실행된 분기 명령어와 분기 목표 명령어를 저장하여 활용.
- 분기 예측
- 자주 사용되는 분기 연산은 굉장히 반복적이다.
- 예측이 맞으면 효과적인데 틀리면 페널티가 발생한다.
# RISC Processor
Reduced Interaction Set Computer. Complex 와 반대. 파이프라인과 잘 맞아 떨어진다.
- 특징
- 실행 명령어 수는 증가해도 처리 시간은 감소 가능
- 명령어의 1사이클 실행이 목표
- 온칩캐시(cpu내 메모리)를 둬서 빠르게 한다. 하드웨어적으로 구현.
- 간단한 명령 코드와 주소 지정 모드 같은걸 하드와이어
- 신속한 참조를 위해 레지스터 집합
- 실수 연산처리를 위한 별도의 코프로세서
# 파이프라인 CPU 성능 분석
- 이론적으로는 세그먼트가 많으면 많을수록 좋지만
- 세그먼트가 일정해야하고
- 순차적으로 실행되어야 하고
- 명령어들 사이에 상호 의존성이 없어야 하고
- 공유 자원의 충돌이 없어야 한다.
# 5. Memory
# 메모리 시스템 이해
- 주기억장치 : 램
- 보조 기억장치 : SSD
- 캐쉬 메모리 : 현재 진행되고 있는 프로그램이나 사용빈도가 높은 임시데이터 저장
# 효율적 메모리 관리 정책
# 컴퓨터 성능 개선을 위한 메모리 관리
# 다양한 기억장치들에 대한 이해
# 6. IO
# 시스템 버스 구성 및 제어
Peripheral Component Interconnect : PCI도 버스다.
레지스터 사이들의 연결은 n^2으로 늘어난다. 이문제 해결을 위해 버스라는 효율적인 방법을 쓴다.
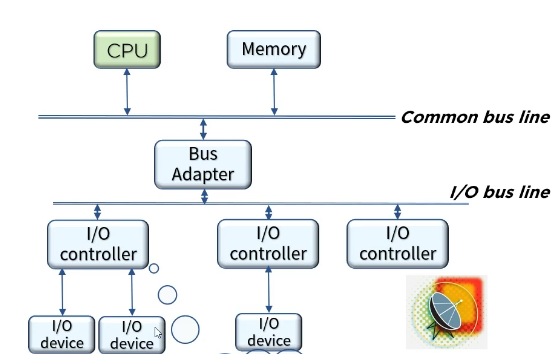
여러 종류의 버스 라인이 존재한다. 이는 버스 어댑터를 통해 둘이 연결된다.
기본적으로 커먼 버스 라인은 메모리와 cpu를 연결한다.
작동 방식
- 동기 : 클락에 의해 시작 정지
- 비동기 : 핸드 셰이킹을 통해서 시작 정지
중재
- 직렬중재
- 병렬중재