
# Operating System
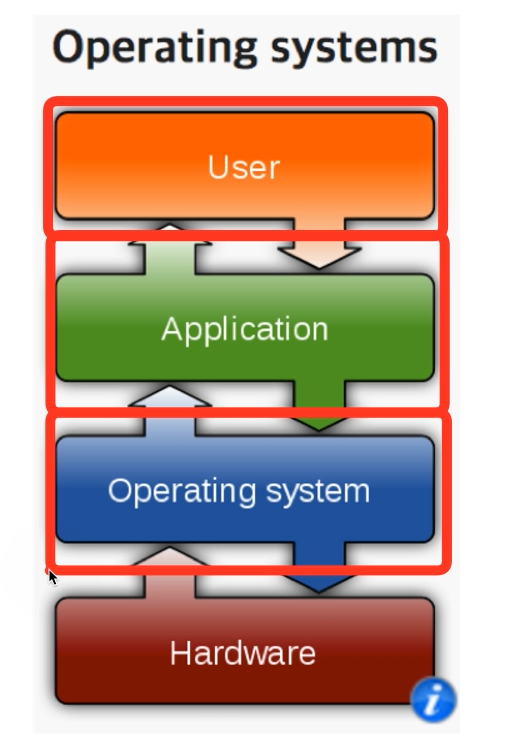
- OS provides
user interfaceto the user. shellprogram provides theinterface- Could be either
CLIorGUI. 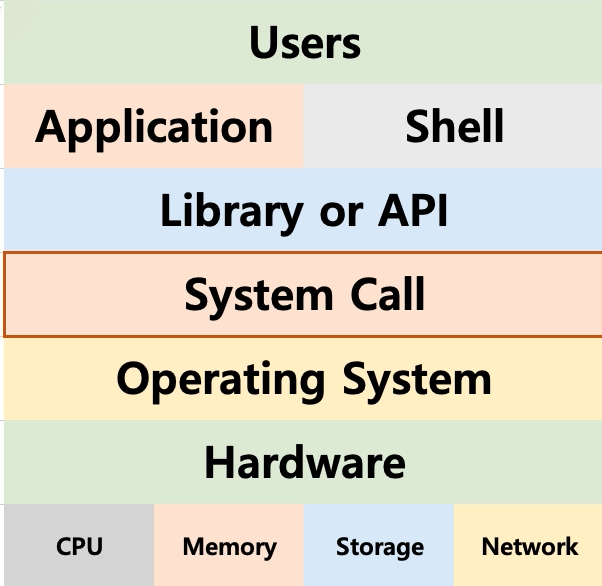
- Could be either
- OS also provides
user interfaceto the application. APIprovides theinterface- In the form of
function.
- In the form of
- You could say that
shellis one type of application.
# System Call
System callis a function provided by the OS.- It can be called to use the OS.
- Majority of
APIs are made to call these system calls. ex) open() - Types
- POSIX API : Used by unix styled OS such as Linux, MacOS ...
- Window API
# OS development order
- Make an OS. (
kernel). - Develop
system call. - Develop
API(library). - Develop
shell - develop
applications.
# kernel? shell?
- kernel : OS의 핵심 부분. 알맹이란 뜻을 갖고 있다.
- shell : 껍데기. kernel의 껍데기
# CPU Protection Rings
- CPU도 권한모드가 있다.
- user mode : used by applications
- kernel mode : used by OS
- 사용자 모드와 커널 모드의 뒤에는 cpu protection ring이라는 개념이 있다.
# Process Scheduling
- Process :
application - Scheduling : 배치처리, 시분할, 멀티태스킹 같이
application을 cpu에 배치하는 방법
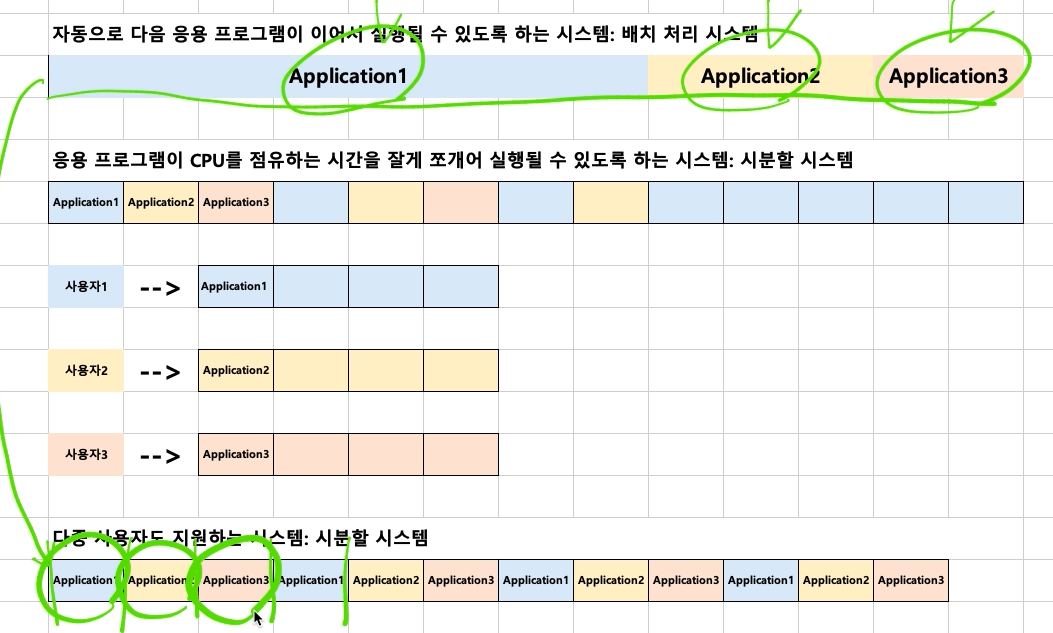
# Batch Processing
- 큐 방식과 비슷한 FIFO
- 하나의 프로세스가 끝나면 그 다음것을 실행시킨다.
# 배치 처리 시스템 / 시분할 시스템 / 멀티 프로그래밍
- 배치 처리는 더이상 안쓰이고 뒤 두개가 쓰이게 되었다.
- FIFO로만 하면 어떤 프로그램은 시간이 너무 오래 걸려서 병목이 생긴다.
- 음악을 재생하면서 워드를 작성하고 싶다면? (동시성)
- 여러 사용자가 하나의 컴퓨터를 쓴다면? (다중 사용자)
- -> 멀티 프로그래밍/시분할 시스템이 나왔다.
# 시분할 시스템
- 다중 사용자 지원을 위해 컴퓨터 응답시간을 최소화 한다.
# 멀티 태스킹
- 단일 cpu에서 여러 응용 프로그램이 동시에 실행되는 것처럼 보이도록 하는 시스템. (현재의 멀티코어와 다르다)
- 음악을 들으며 문서 작성을 한다.
- 매우 짧은시간동안 각각의 프로그램을 바꿔가면서 실행한다.
- 10~20ms 단위로 application 이 바뀐다.
- 사용자에게는 동시에 실행되는 것처럼 보인다.
- 기본적으로는 시분할 시스템과 원리가 비슷하다.
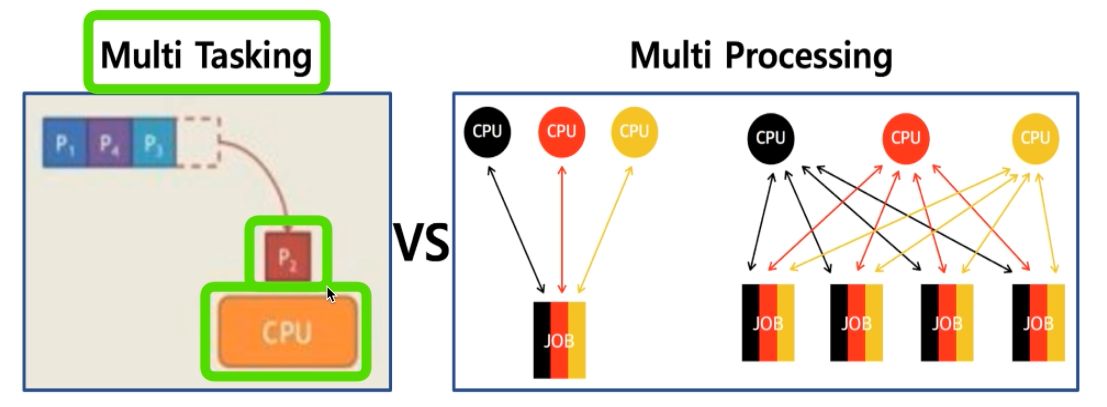
# 멀티 태스킹 vs 멀티 프로세싱
- 멀티 태스킹 : 단일 cpu
- 멀티 프로세싱 : 여러 cpu
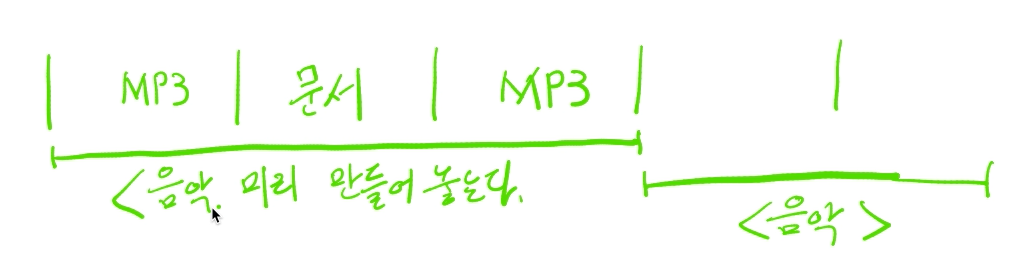
# 멀티 프로그래밍
- 최대한 cpu를 많이 활용하도록 하는 시스템
- cpu에 응용프로그램이 있다고 하더라도 다른 작업을 한다고 cpu를 활용하고 있지 않을때가 있다.
- 응용 프로그램이 실행되다가
파일을 읽는다. 저장매체는 cpu에 비해 굉장히 느린 아이다. 이 과정에서 cpu는 쉬게 된다.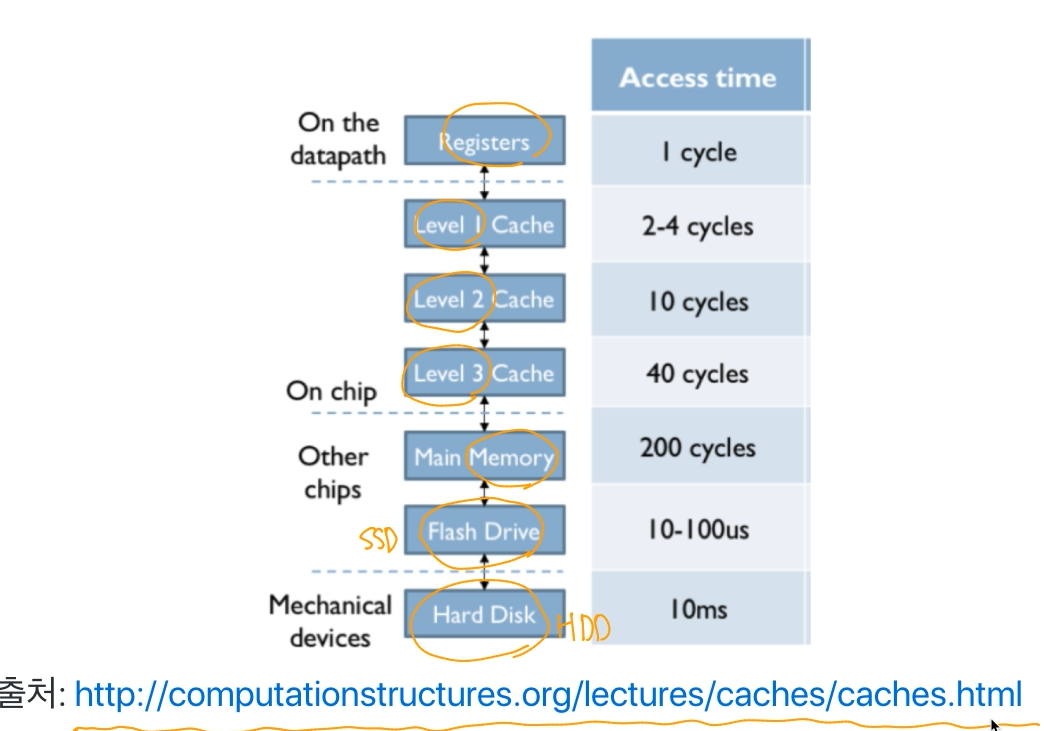
- ssd만 되더라도 몇만 싸이클을 대기해야 된다.
프린팅을 한다. 프린터가 끝날때까지 작업을 못한다면? cpu는 그냥 쉬는것이다.
- 응용 프로그램이 실행되다가
- 이 때에 작업 바꿔치기를 통해서 지금 필요한 응용 프로그램을 cpu에 넣어서 작업처리 속도를 빠르게 할 수 있다.
# Process
# Process
- 실행 중인 프로그램
- 응용 프로그램 != 프로세스
- 응용 프로그램은 여러 개의 프로세스로 이루어질 수 있음
- 하나의 응용 프로그램은 여러개의 프로세스와 상호작용을 하면서 실행 될 수 있다.
- IPC
# Scheduler
프로세스를 실행시킨다.
어느 순서로 실행하고 교체할지 스케쥴링 알고리즘에 의해 결정된다.
Goal :
- 프로세스 응답 시간을 짧게 : 시분할 시스템
- CPU 활용도를 높인다 : 멀티 프로그래밍
기본적인 스케쥴링 알고리즘들
FIFO : 저장매체, 외부장치와 상호작용 없이 쭉 CPU를 사용한다. 가장 간단하고 배치처리 시스템과 유사하다.
SJF : shortest job first. 실행시간이 가장 짧은것부터 먼저 실행.
Priority Based :
- 정적 우선 순위 : 프로세스마다 우선순위를 미리 지정. 모든 프로그램에 우선순위 미리 주는게 쉽지 않다.
- 동적 우선 순위 : 스케쥴러가 상황에 따라 우선순위를 동적으로 변경
Round Robin Scheduler :
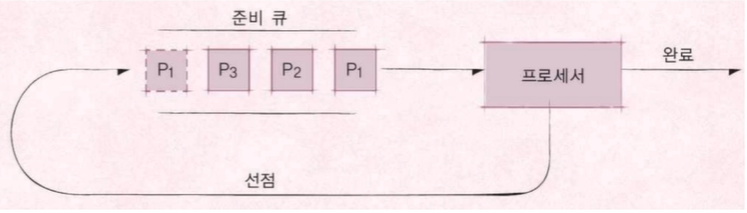
시분할 시스템을 위한 스케쥴러. 특정 시간이 안끝났더라도 다시 큐 뒷편으로 보내고 다음것을 한다.
# 멀티프로그래밍과 wait
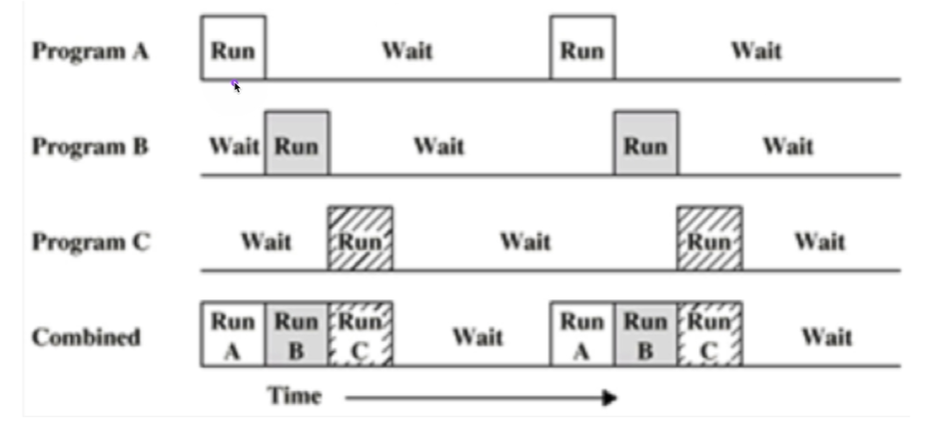
- 위와 같은 효율적인 배치를 위해서는 cpu가 각 프로세스의 상태를 알고 있어야 한다.
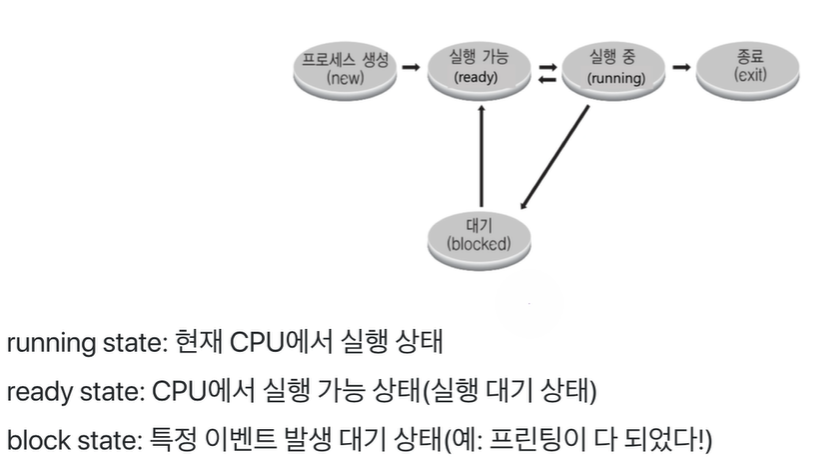
# Process Scheduling

- 무엇부터 실행할 것인가?
- 시간차에 의해 먼저 들어온쪽이 Ready State Queue에 들어온다.
- ready state에서 fifo해서 running으로 들어가고 cpu에 할당된다.
- 단위가 1을 넘어가면 꼬리는 ready의 제일 끝으로 들어간다
- wait가 걸리면 block 으로 들어간다
- block이 끝나면 ready로 다시 들어간다.

# 프로세스 구조
- Stack
- Heap
- Data
- BSS : 초기화 되지 않은 전역 변수
- DATA : 초기값이 있는 전역 변수
- Text
# 스택 오버플로우
해킹 기법 중 하나
# 컨텍스트 스위칭
- cpu에서 돌아가는 프로세스를 바꿔주는 것을 컨텍스트 스위칭 이라고 한다.
- Context
- Program Counter : CODE 부분에서 다음 실행될 라인을 가르킴
- Stack Pointer : STACK에서 다음 실행될 빈 공간을 가르킴
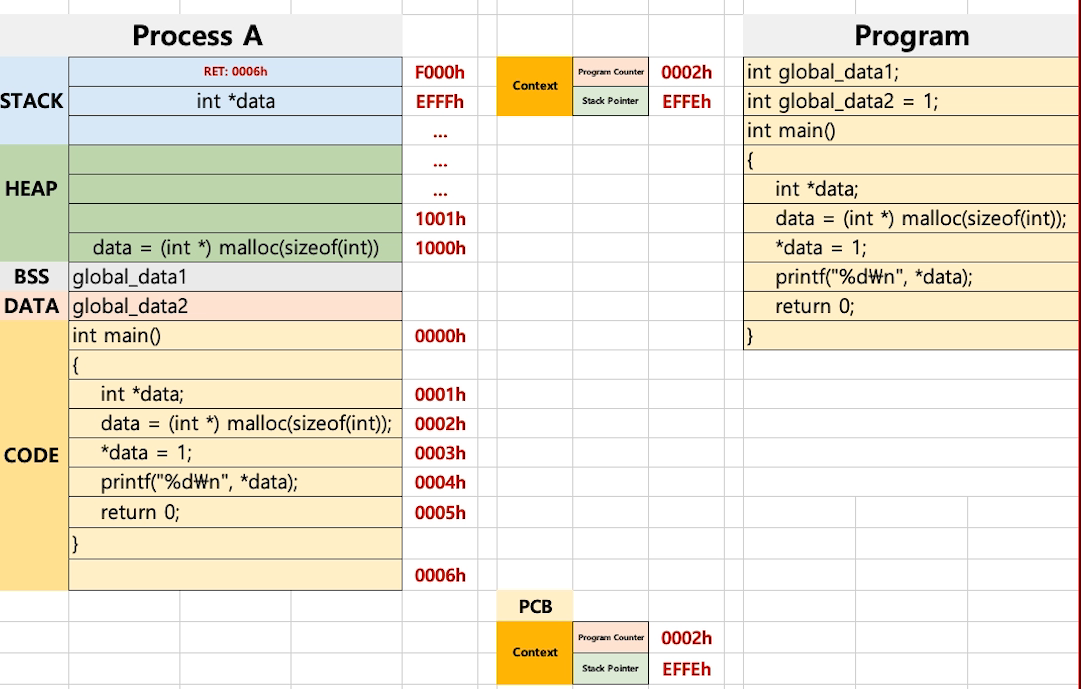
- PCB(Process Control Block)라는 특수한 공간에 Context가 저장되어 프로세스가 바뀔대마다 위치를 알려준다.
- Process ID
- Register 값 (Program Counter, Stack Pointer)
- Scheduling Info(Process State)
- Memory Info
- 와 같은 값들, 즉 프로세스 실행 상태를 캡처/구조화해서 저장
# 컨텍스트 스위칭의 과정
- 컨테스트 스위칭은 ms 단위로 일어난다.
- 컨텍스트 스위칭이 짧아야지 전체 작동시간을 줄일 수 있다.
- 그래서 컨텍스트 스위칭은 이식성은 떨어지더라고 속도를 높이기 위해 어셈블리어로 작성하기도 했다. 단점은 서로 다른 cpu 아키텍처가 등장할때마다 새로운 프로그램을 작석해야하고 시간이 굉장히 오래 걸렸다.
- 컴파일러 등장으로 이식성을 높일 수 있었다. 속도는 조금 떨어짐
- 리눅스는 각각의 cpu별로 컨텍스트 스위칭하는 프로그램을 어셈블리어로 다 짜놨다.
# Inter-Process Communication
프로세스간 통신하기 위한 방법 : IPC
프로세스는 다른 프로세스의 공간을 직접적으로 접근 할 수 없다.
메모리 주소는 자기 프로세스의 공간만 가르킬 수 있다.
프로세스간 통신이 필요한 경우?
- cpu core가 여러가지여서 동시에 실행 하는 경우(병렬처리)
shared.txt : 저장매체는 공유하기 때문에 파일을 하나 만들어서 업데이트 하면서 사용하는 방법이 있다. 그러나 실시간 update여부를 다른 프로세스에 알려주기 어렵고 저장매체를 굉장히 느린 방법이기 때문에 한계가 있다.
# 실제 프로세스 : Linux
- 리눅스의 경우 4기가 프로세스를 사용
- 3~4기가 공간은 운영체제가 사용(kernel space).
- 0~3기가를 프로그램이 사용(user space).
- user space는 kernel space도 접근할 수 없다.
- 프로세스를 띄울때마다 운영체제를 불러오면 용량 낭비가 심하다
- 그래서 사실 주소는 가상메모리고 실제 물리 메모리의 커널은 동일한 곳에서 꺼내서 쓴다.
- 이러한 커널 공간을 이용해서 IPC 기법들이 나온다.
# 다양한 IPC 기법들
대부분이 커널 공간을 활용한다.
file 사용
Message Queue : FIFO 정책으로 데이터 전송하기 때문에 순서가 중요하다. 동일한 키값을 써야 메시지를 주고 받을 수 있다. 부모/자식 뿐만 아니라 어느 프로세스간에도 괜찮다.
Shared Memory : 커널에 메모리 공간을 만들고 해당 공간을 변수처럼 사용. FIFO가 아니고 메모리주소로 변수처럼 접근한다.
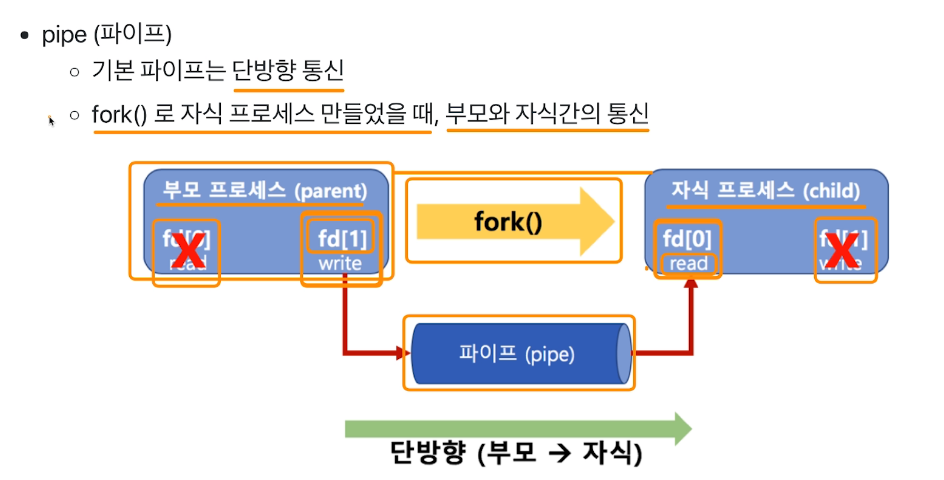
Pipe : 단방향 통신. fork할때 부모와 자식간 통신
Signal : Unix에서 30년 이상 사용된 전통적 기법. 커널 또는 프로세스에 이벤트 발생을 알린다.

Semaphore
Socket: 네트워크 통신을 위한 기술. 기본적으로는 클라이언트와 서버등 두개의 다른 컴퓨터간의 네트워크 기반 통신 기술. 그렇지만 컴퓨터내에서 플세스간 통신에도 사용될 수 있다.
# Thread
# Thread
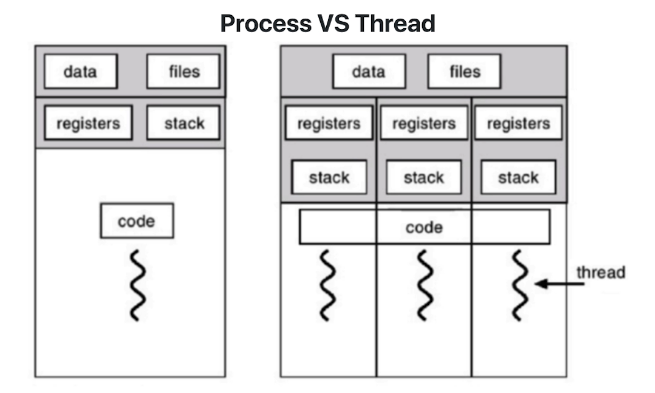
Light weight process
프로세스 : 프로세스 간 데이터 접근 불가(ipc 사용해야함)
쓰레드 :
- 하나의 프로세스에 여러개의 스레드 생성 가능.
- 여러개의 스레드 동시에 실행 가능
- 프로세의 데이터를 모두 접근 가능
- 스택과 힙사이에 공간을 만들어서 쓰레드를 위한 스택을 따로 만들수 있다. 각각의 쓰레드 스택을 위한 Stack Pointer, Program Counter들이 다 생긴다.
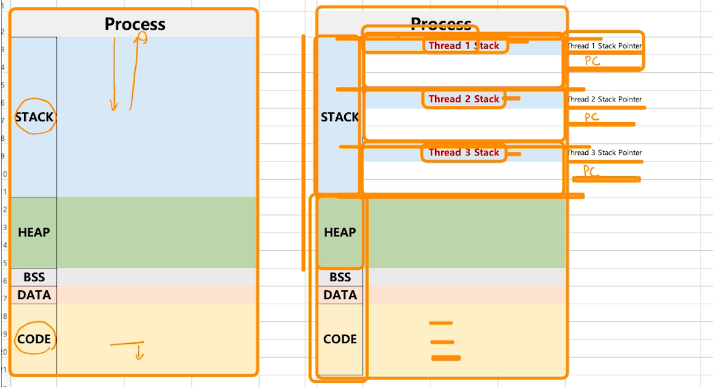
- 나머지 영역들은 다 공유하고 있기 때문에 쓰레드는 별도의 ipc가 필요 없다.
# Multi Thread
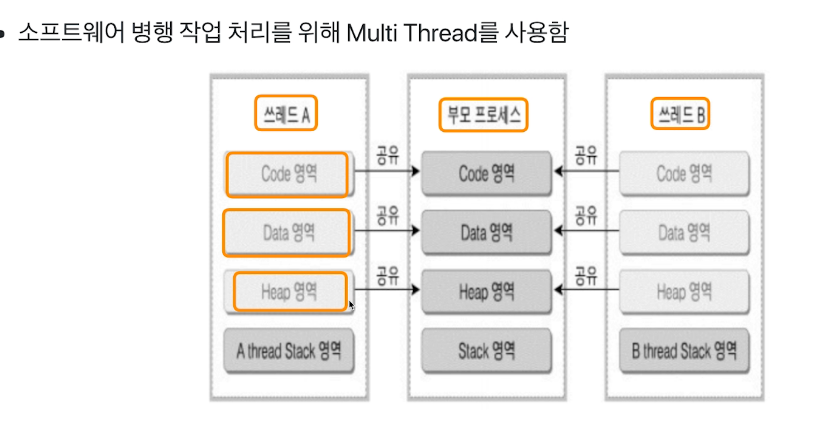
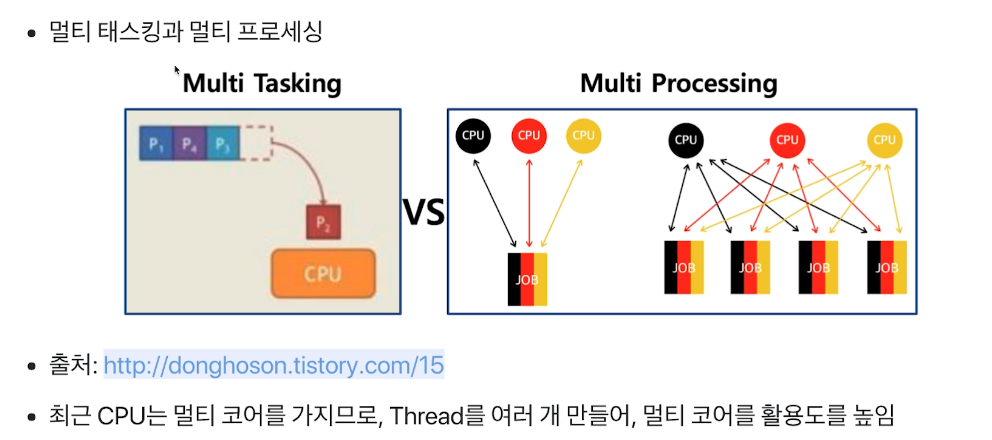
- multi tasking : 하나의 cpu에 여러가지 프로세스를 바꿔가면서 실행하면서 여러개가 동시에 실행되는 느낌을 준다.
- multi processing : 여러 cpu에 여러 프로세스를 나눠주면서 병렬 실행을 통해 실행속도를 높인다.
- 여기서 하나의 job을 여러 cpu에 나눠주는 방법이 thread를 활용한다
- thread를 여러개 만들어 멀티 코어의 활용도를 높일 수 있다.
# Thread의 장점
사용자에 대한 응답성 향상
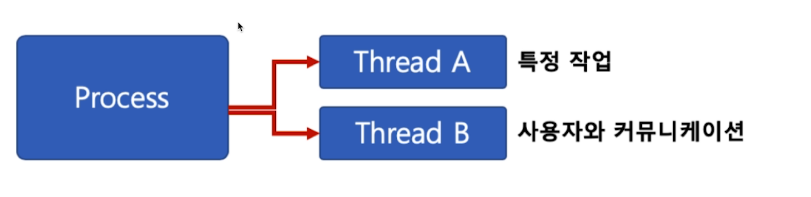
자원 공유 효율 : 프로세스는 IPC가 필요한데 쓰레드는 필요 없다. 프로세스는 각각 생성하면 메모리를 차지하는데 쓰레드는 하나의 프로세스안에서일어나기 때문에 효율적이다.
작업이 분리되어 코드가 간결하다. 쓰레드 하나가 함수 하나처럼 작성되기 때문이다.
# Thread의 단점
쓰레드 중 하나만 문제가 있어도 전체가 영향을 받는다.
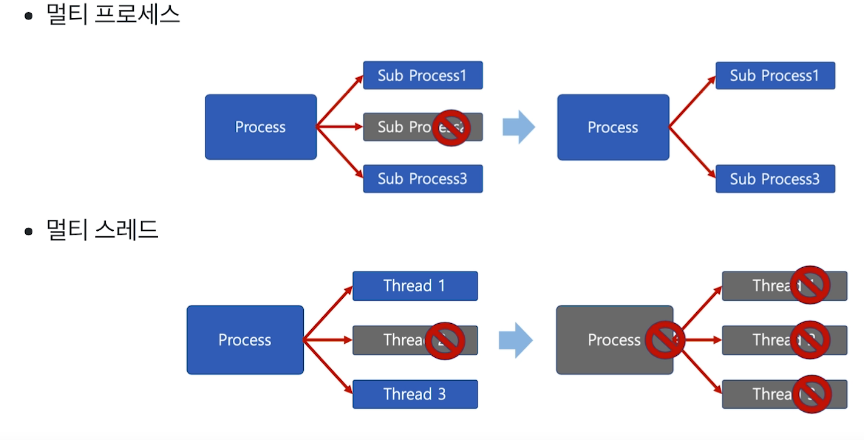
쓰레드가 많으면 context switching이 잦아져서 성능이 저하된다.
ex) 리눅스에서는 thread를 process와 동일하게 스케쥴링해서 쓰기 때문에 context switching이 자주 일어난다.
# Thread vs Process
- 프로세스는 독립적, 스레드는 프로세스의 서브셋
- 프로세스는 독립 자원, 스레드는 공유 자원
- 프로세스는 자신만의 주소영역, 스레드는 주소영역 공유
- 프로세스는 ipc 통신 사용, 스레드는 안 사용
# Synchronization 이슈
- 스레드는 스케쥴러에 의해서 실행이 번갈아가면서 일어나는데 변수값 접근할때 순서가 엉키면 동기화 이슈가 발생하게 된다.
- 디버깅이 굉장히 어렵다
- Mutual Exclusion (상호 배제)를 통해서 막는다.
- 임계 자원(critical resource) : 막아야되는 변수
- 임계 영역(critical section) : 막아야 되는 코드 영역
# Semaphore
locking mechansim에는 크게 두가지가 있다.
- Mutex(binrary semaphore) : 임계구역에 하나의 스레드만 들어갈 수 있게
- Semaphore : 임계구역에 여러 스레드, counter를 통해 동시에 리소스 접근 가능한 스레드 수 제어
순서
- S : 세마포어 값. 초기값만큼 여러 프로세스가 동시 임계 영역 접근 가능
- P(검사) : 임계 영역에 들어가면서 S값을 1차감. S가 0이면 대기.
- V(증가) : 임계 영역에서 나올때 S값을 1증가
대기
- Busy waiting(바쁜 대기) : 프로그램에는 대기가 없기 때문에 for loop을 돌면서 대기하는 수밖에 없다. 이로인해 cpu를 사용하게 되어 성능이 저하된다.
- Waiting queue(대기 큐) : 특별한 큐를 만들어서 넣음으로써 for loop을 사용하지 않을 수 있다. sleep을 시켜놓고 s가 0보다 커지면은 wake를 시킬 수 있다.
# Deadlock & Starvation
# Deadlock
두 개 이상의 작업이 서로 상대방의 작업이 끝나기만을 기다려서 진행이 안되는 상태
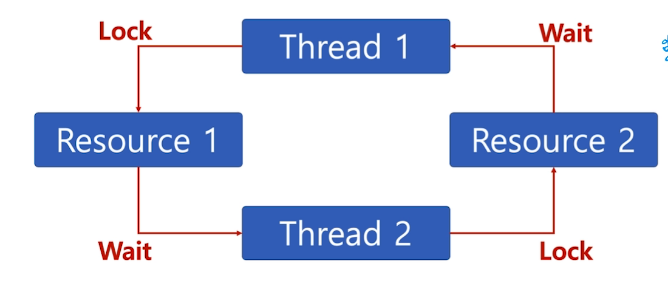
- Deadlock 발생 조건
- Mutual Exclusion : 프로세스들이 자원에 대한 배타적 통제권 요구
- Hold and wait : 프로세스들이 할당된 자원을 가진상태에서 다른 자원을 요구하며 대기
- No preemption : 프로세스들끼리 자원을 뺏을 수 없다.
- Circular wait : 각프로세스는 순환적으로 자원을 요구한다.
# Starvation
프로세의 우선순위가 낮아서 자원을 계속 할당 받지 못하는 상태
Deadlock은 여러 프로세스가 동일 자원 점유를 요청할때 발생
Starvation은 동일 자원 점유를 위해 경쟁시 특정 프로세스는 영원히 자원할당이 안되는 경우를 의미.
우선순위를 수시로 변경 or 오래 기다리면 우선순위를 높여주는 방법으로 해결 가능.
# 가상 메모리
리눅스는 하나의 프로세스가 4gb
통상 메모리는 8gb, 16gb
그러면 멀티프로세싱을 어떻게 하는가? 한번에 두개, 네개밖에 불가능?
실제로는
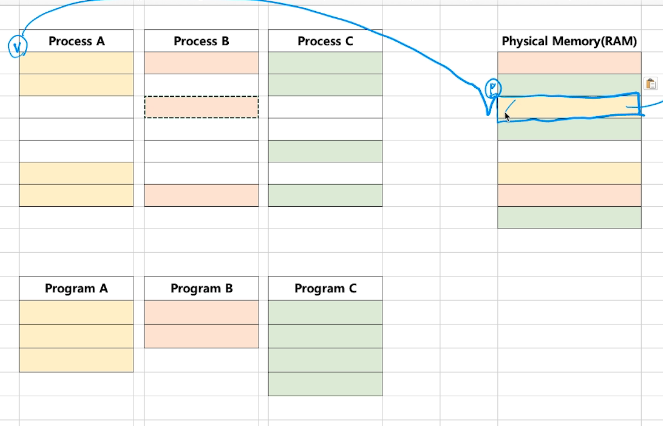
이런식으로 쓴다. 이것을 가상메모리라고 한다.
여러 프로세스를 동시에 실행하는 경우에 필요하다.
기본 아이디어
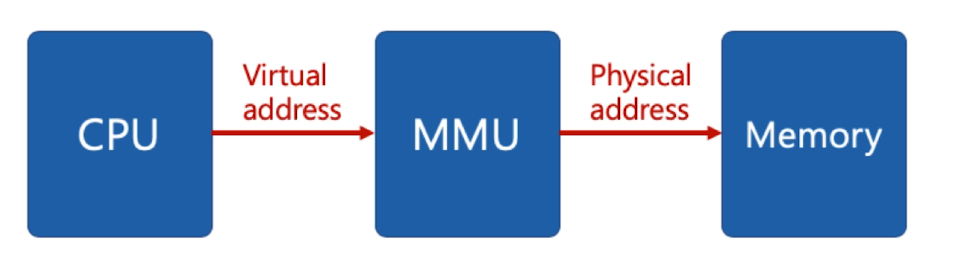
- 프로세스는 가상 주소를 사용하고 실제 해당주소에서 IO/write할때 물리주소로 바꿔주면 된다
- 가상 주소 : 프로세스가 참조하는 주소
- 가상 메모리 : 가상 주소와 물리 주소를 변환해 준다.
- MMU (Memory management unit) : 가상주소 물리주소를 변환해주는 하드웨어를 제공해서 속도를 빠르게 한다.
- 물리 주소 : 실제 메모리 주소
# 페이징 시스템
가상 메모리에서 가장 많이 쓰이는 메커니즘 중 하나
페이징 개념
- 크기가 동일한 페이지로 가상주소와 물리주소를 관리
- 하드웨어 지원이 필요
- intel x86에서는 4kb, 2mb, 1gb 지원
- 리눅스에서는 4kb 페이지 사용
- 페이지 번호 기반으로 가상/물리 주소 매핑한다.
PCB에 Page Table 구조체를 가르키는 주소가 있음


# 다중 단계 페이징 시스템
- 4kb 짜리 c프로그램을 만들었는데 4기가를 다 써야 하는가?
- 데이터가 있는 영역만 페이지를 만드는 것을 다중 단계 페이징 시스템이라고 한다.
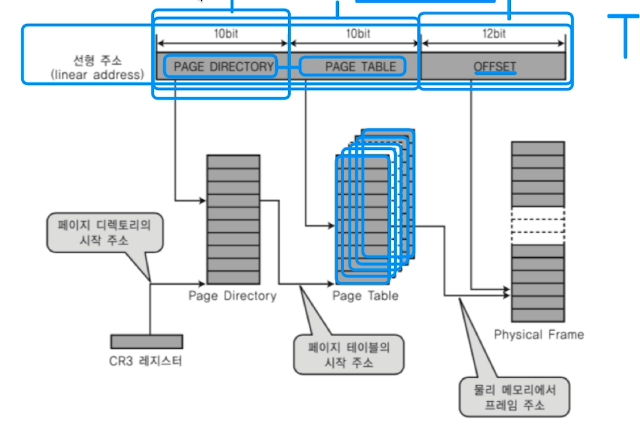
- 메모리 접근 무려 세번이나 해야돼서 굉장히 느리다.
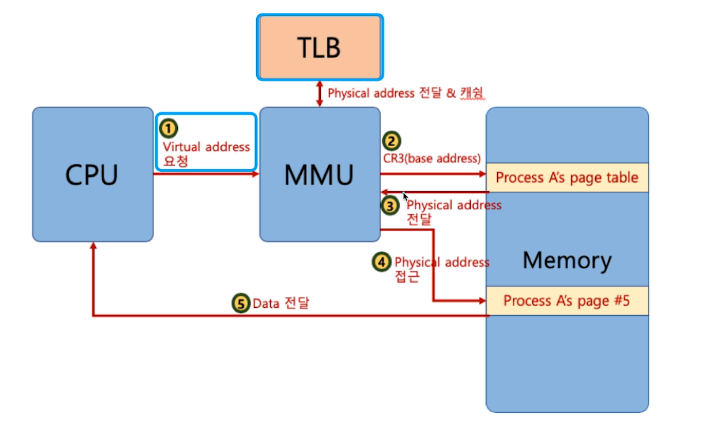
- Translation Lookalike Buffer : 캐쉬. 최근 변환한 가상메모리-물리메모리가 저장돼있어서 page table 위해 메모리 접근 없이 바로 메모리에 갈 수 있다.
# 페이징 시스템과 공유 메모리
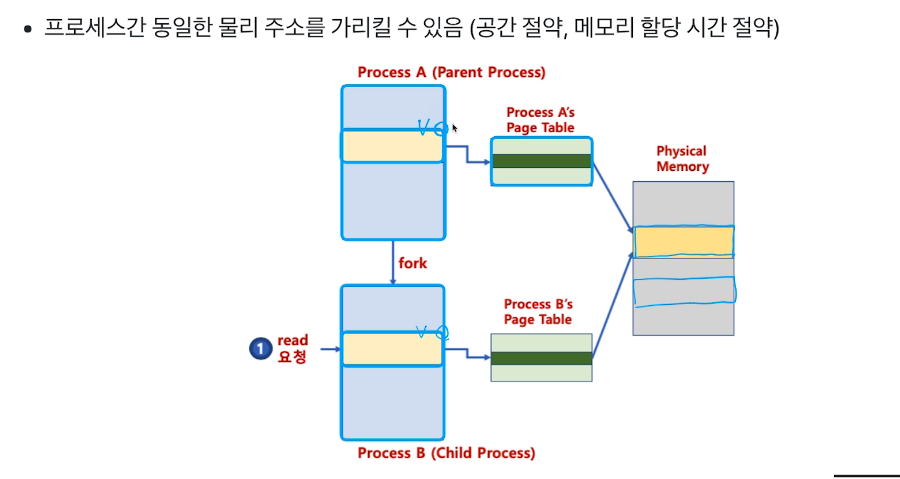
프로세스마다 1기가씩 운영체제 메모리를 가지고 있다면 굉장히 아깝다
그렇지만 물리메모리를 가르키는 부분은 동일하기 때문에 사실 아깝지 않다.
이런것이 페이징 시스템을 통해서 구현이 될 수 있다.
또한 forking을 할때 실제로 복사하지 않고 그냥 page table을 통해서 동일 부분을 가르키게 한다.
write를 하게 된다면 그때서야 복사 후 page pointer를 변경하는 방법으로 진짜 복사를 시작한다
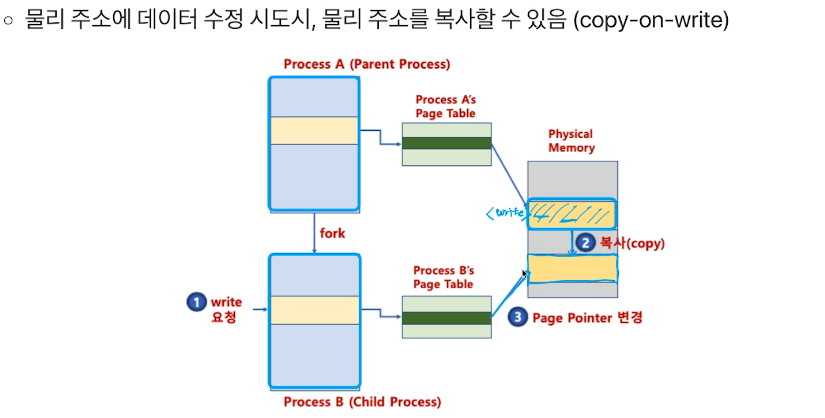
# Demand Paging
- 프로세스의 모든 데이터를 메모리에 적재하지 않고 실행 중 필요할때만 메모리에 적재함.
- anticipatory paging(선행 페이징)과 반대개념이다.
# Page fault interrupt
- 페이지가 물리 메모리에 없을 때 발생
- page fault 인터럽가 일어나면 해당 페이지를 물리 메모리에 올림
- demand paging을 위한 기본 기술임
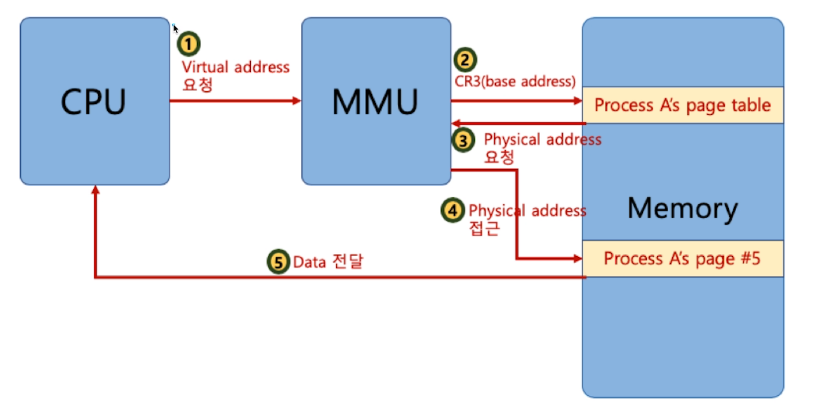
# 전체 과정
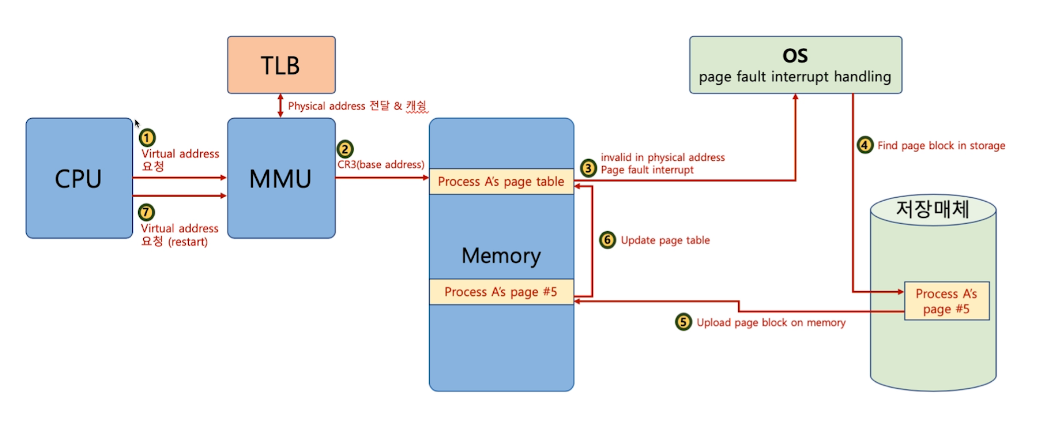
- cpu가 virtual address 요청
- 먼저 TLB를 확인한다
- 없다면 CR3 레지스터를 이용해서 page table에 접근
- page table에서 valid/invalid 비트를 통해 물리 메모리 저장여부를 확인한다
- 저장이 돼있다면 물리메모리 주소를 리턴하고 메모리에 접근가능
- 없다면은 page fault interrupt가 일어난다
- IDT에 간다
- page fault번호를 통해 os의 함수를 갖고온다
- OS가 실행 프로세스에서 데이터를 갖고와서
- 데이터를 메모리에 올려준다
- page table을 업데이트 해준다.
- cpu에 다시실행하라고 알려준다
딱 봐도 tlb에서 바로 하는것보다 매우 느리다. 페이지 폴트가 자주 일어나면 시간이 오래 걸린다. 그렇지만 미리 예측해서 물리 메모리에 올리는 것은 신의 영역이다. 이를 해결하기위한 여러 알고리즘이 있다.
# 페이지 교체 정책
여러 프로세스가 있을때 물리메모리를 누가 쓸 것인가?
- 다양한 알고리즘이 가능하다. 단순하게 FIFO를 생각할 수 있다.
- 최적 페이지 교체 알고리즘 : 불가능하다. 이상향.
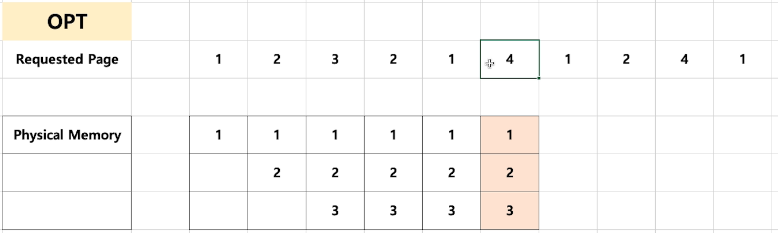
- 이때 3번을 4번으로 교체하는 것이 가장 이상적이다.
- 그렇지만 예측 불가.
- LRU : 가장 오래전에 쓴 페이지를 없앤다.
- LFU : 가장 적게 사용된 페이지를 없앤다.
# Thrashing
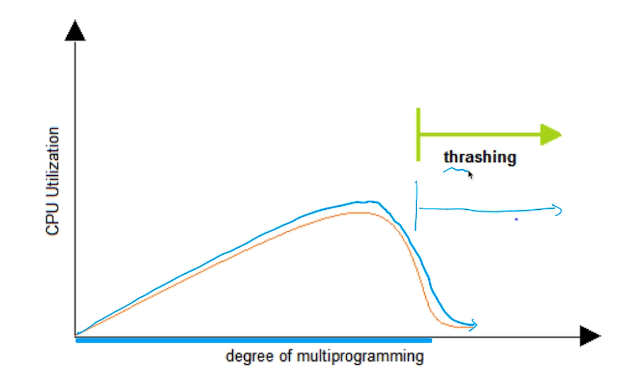
- page fault, page swap만 자주일어나서 실제로는 뭔가를 하지 못하는 단계
- 프로그램을 너무 많이 띄워놓으면 안된다.
- 많이 하고싶으면 메모리를 추가로 달아줘야한다.
# Segmentation
- 가상 메모리를 서로 크기가 다른 논리적 단위인 세그먼트로 분할
- 이에 비해 페이징은 같은 크기의(4kb) 블록으로 분할
- 80296이라는 cpu가 보호모드(protection ring)을 지원하고 kernel/user를 지원하게 됐다.
- 이로 인해 기존의 cpu소프트웨어는 지원하지 않게 됐다.
- 이를 실행하기위해서 호환모드를 만들었다.
- 부팅시에 운영체제가 리얼모드로 실행이되고 그 이후 보호모드가 된다.
- 이게 인텔의 x86이며 최대 1gb 프로세스 사용, 세그먼트로 나누게된다.
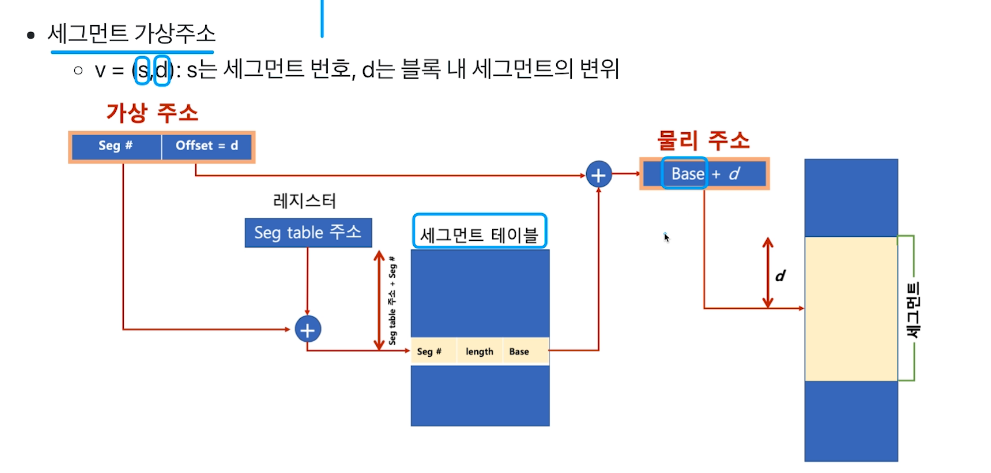
- 페이징 시스템과 거의 유사하다.
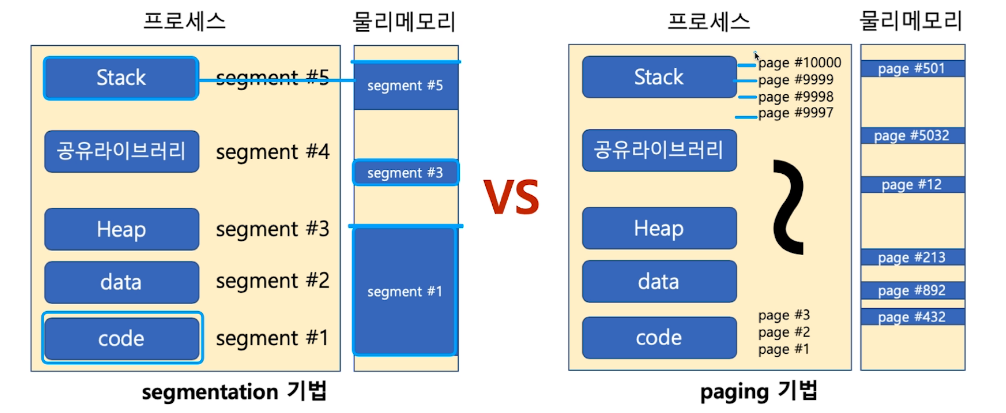
- 페이징 기법은 4kb를 다 채우지 못하면 공간 낭비가 발생
- 세그멘테이션 기법은 물리 메모리가 원하는 크기의 연속 메모리를 제공해주지 못하면 문제가 생긴다.
- 리눅스는 다양한 cpu를 다 지원하기 때문에 기본인 페이징 기법을 기반으로 구현돼있다.
# File system
운영체제가 저장매체이 파일을 쓰기위한 자료구조/알고리즘
# 파일 시스템이 만들어진 이유?
- 0과 1을 어떻게 저장할 것인가?
- 비트로 관리하기에는 너무 양이 많다.
- 블록 단위(4kb)로 관리하기로 한다.
- 사용자가 블록 고유 번호 관리할수없다.
- 추상화를 통해 파일을 만들어야 한다. 파일은 블록단위를 관리한다.
- 저장의 효율적 방법?
- 연속적인게 좋을 것 같았다
- 근데 보니까 파일 사이즈가 변경되기때문에 불연속 공간 저장 기능 지원이 필요하다. ->외부 단편화 문제
- 블록 체인 : 블록을 링크드 리스트로 연결. 첫번째 블록의 주소를 갖고있으면 그 블록에 다음 블록의 주소가 저장돼있어서 찾을 수 있다. 문제는 끝 블록을 찾으려면 처음부터 다 가야되기 때문에 단점이 있다.
- 인덱스 블록 기법 : 각 블록의 주소를 별도로 저장해놔서 원하면 바로 갈수있게 저장
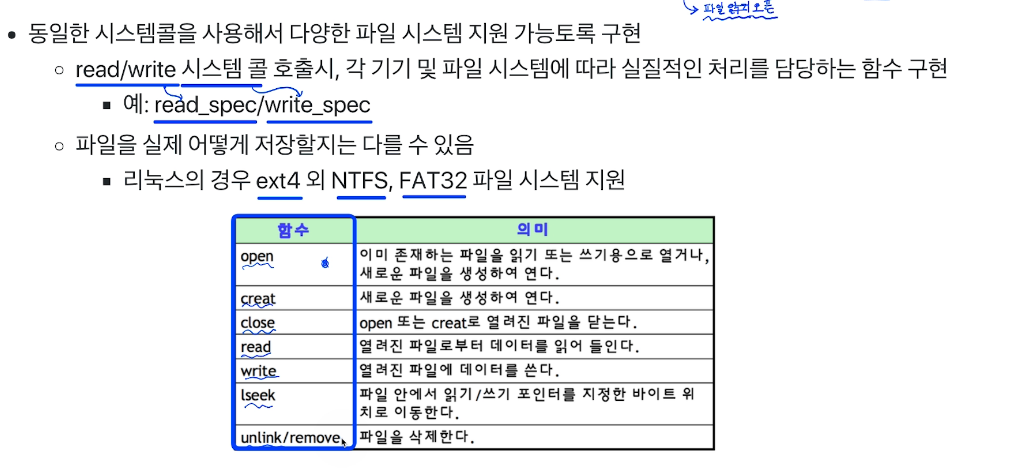
# 다양한 파일 시스템
Windows : FAT, FAT32, NTFS
- 블록 위치를 FAT이라는 자료구조에 저장.
Linux(unix) : ext2, ext3, ext4
- 인덱스 블록 기법인 inode 방식을 사용
그러나 시스템콜이 파일 시스템에 따라 바뀌면 너무 복잡하기 때문에 시스템함수는 동일하게 호출하면 알아서 처리해준다. 내부적으로는 파일 시스템 마다 다르다.
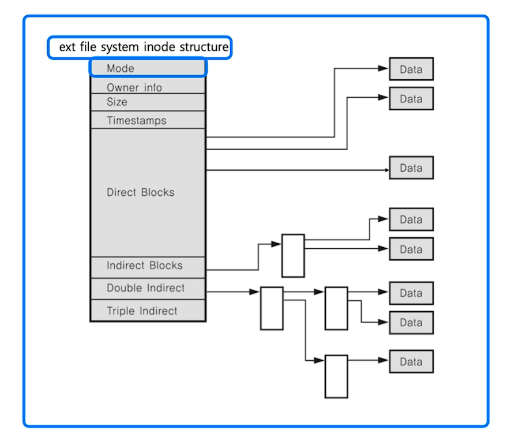
# inode 파일 시스템
- 기본 구조
- 수퍼 블록 : 파일 시스템 정보
- 아이노드 블록 : 파일 상세 정보 (메타데이터라고도 함. pcb에 저장)
- 데이터 블록 : 실제 데이터 (4kb 단위)
- 파일은 inode 고유값에 의해 관리된다. 파일 이름은 inode 번호와 매칭.
- 프로세스 생성 -> 프로세스 id 생성 -> pcb에 저장 -> 관리
- 파일 생성 -> inode 번호 생성 -> inode블록 생성 -> 관리
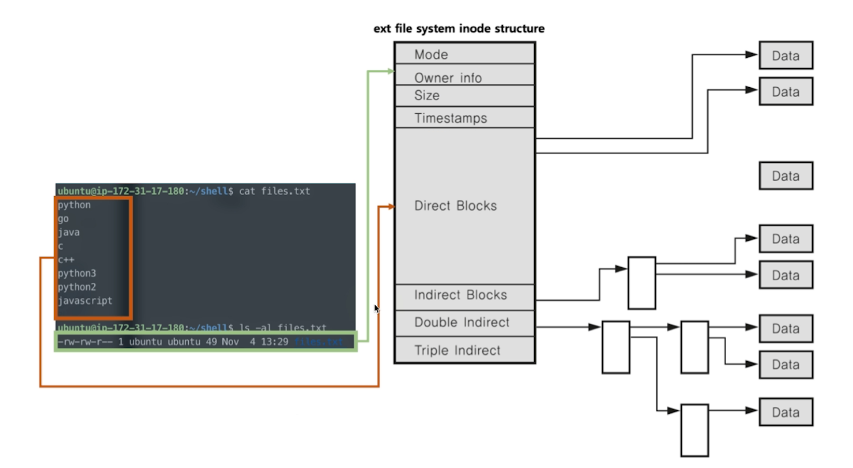
# inode 구조
- inode 기반 메타 데이터 : 권한, 소유자, 사이즈, 생성시간, 저장 위치 등 (위쪽 네블록)
- direct block : 데이터 블록의 주소를 갖고 있다. 12개.
- direct block은 12개. 가르키는 data는 1kb~4kb정도다. 그러면 전체용량이 48kb밖에 안된다고? 동영상 파일은 몇기간데 어떻게 하는가. 그래서 아래 세가지 블록들이 있다.
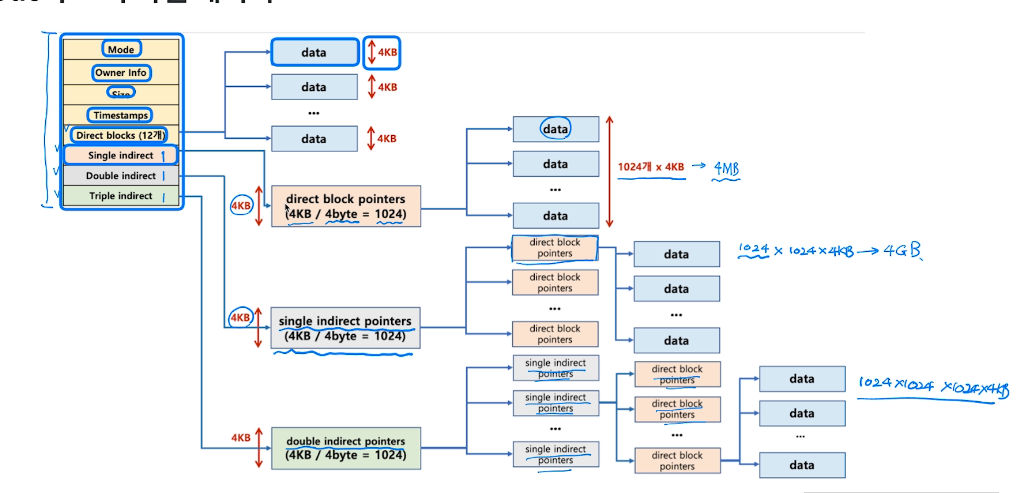
- direct block pointer에는 pointer를 1024개 저장함으로써 1000배의 데이터를 저장할 수 있다.
- 이를 반복하는 double과 triple을 통해 큰 용량을 저장할 수 있다.
# directory entry
/home/ubuntu/link.txt
- dentry라고 한다.
- 각 엔트리는 해당 디렉토리 파일/ 디렉토리 정보를 갖고 있다.
- 이를통해 해당파일의 inode를 얻게 된다.
# 가상 파일 시스템
- 전통적 unix에서 파일 시스템 인터페이스르 확장해서 네트워크까지 적용한다.
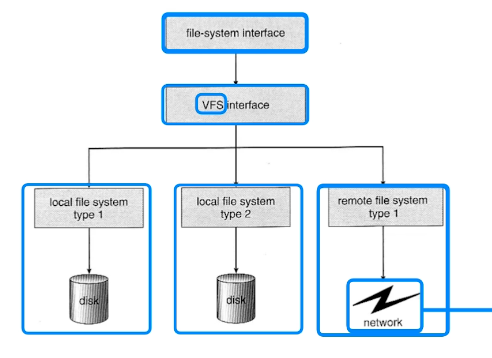
- 모든 디바이스를 파일처럼 다룰수있게 만들었다.
- 마우스, 키보드, 모든 자원을 추상화시켜서 파일 인터페이스로 활용한다.
- 모든 인터렉션은 파일을 읽고 쓰는 것처럼 이루어져있다.
# Booting
컴퓨터를 키는 동작
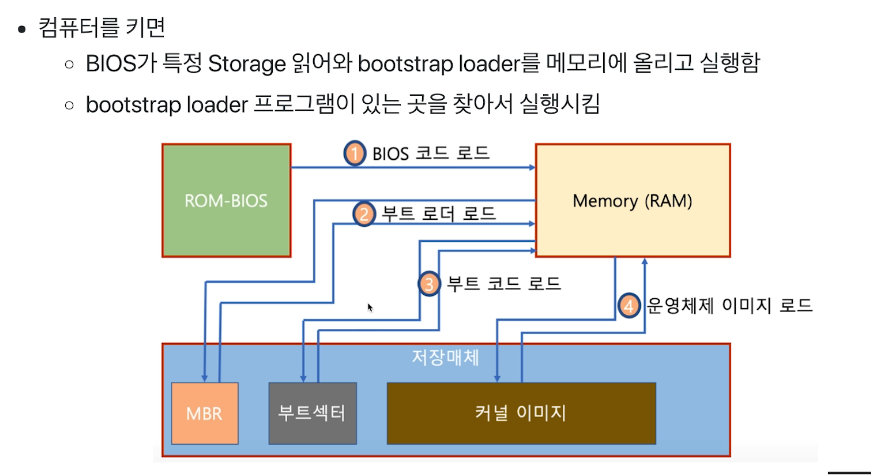
- Boot program : 운영체제 커널을 Storage에서 물리 메모리로 복사하고 커널의 처음 실행위치로 pc를 가져다 놓는 프로그램
- pc 부팅시 메모리는 텅 비어 있다.
- 그렇지만 모든 프로그램은 메모리에서 cpu로 가면서 실행된다.
- 텅비어있으면 어떤 프로그램이 운영체제를 메모리로 가져온단 말인가?
- ROM : 특별한 램으로 컴퓨터가 꺼져도 메모리가 남아있으며 BIOS 프로그램이 들어있다.
- 컴퓨터가 켜지면 cpu는 rom의 특정 주소를 실행한다. 미리 매핑이 되어있다. (FFFF0H 라고 설정돼있음)
- 그러면 bios의 일부가 실행된다. (느림)
- 이게 bios프로그램 전체를 메모리에 올리게 된다. (이제 빨라짐)
- bios 프로그램은
- 하드웨어 초기화
- 저장매체(hdd, ssd) 맨앞의 MBR(Master Boot Record)를 찾아가서 읽어온다. 이게 부트 로더 라는 프로그램이다.
- 부트 로더를 이제 메모리에서 실행시킨다. 여기엔 파티션 테이블이란게 들어가있다.(C:/, D:/, /). 드라이브 정보들을 갖고와서 메인 파티션이 뭔지 알게된다.
- 부트 로더는 메인 파티션의 부트 섹터라는 주소로 간다. 이안에 부트 코드가 있다.
- 부트 코드를 갖고와서 해당 파티션의 커널 이미지(실행파일)을 메모리에 갖고온다.
- 그뒤 커널이미지가 실행되면서 윈도우 로딩화면이 시작된다.
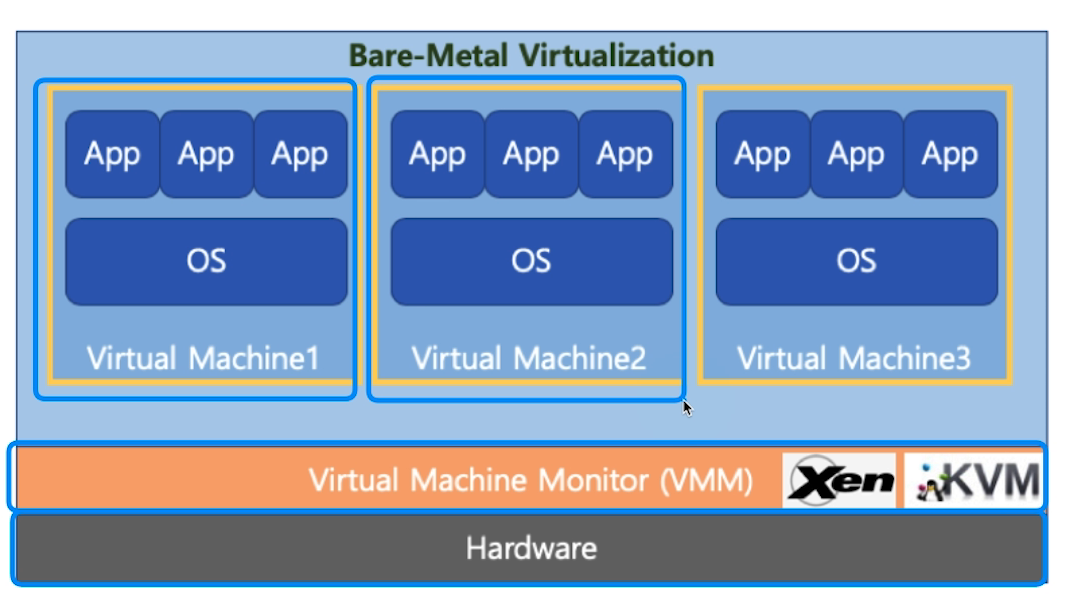
# 가상 머신
하드웨어를 emulate하는 기술
종류는 두가지로 나뉜다
Type 1 : 하드웨어 위에 VMM(혹은 하이퍼 바이저)라는 SW가 설치되어있고 그 위에 VM들이 돌아간다.
Type 2 : 하드웨어에 일반적 OS가 설치돼 있고 거기에 VMM이 설치되어 있다.
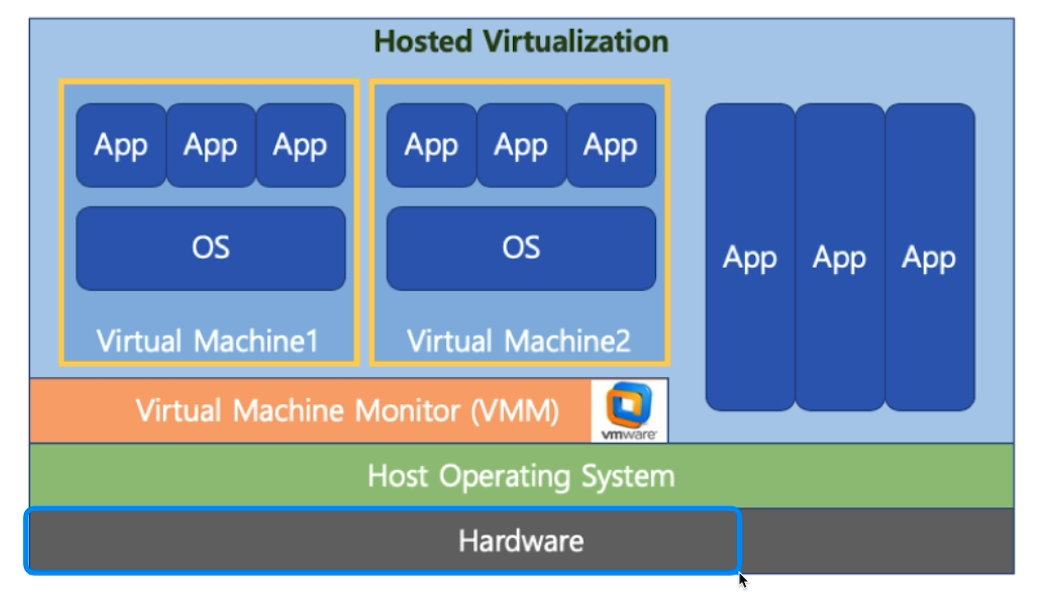
역시 Type 1 이 더 성능이 좋다.
전가상화 반가상화로 나눌 수 있다.
- 전가상화 : VMM(하이퍼바이저)이 하드웨어처럼 동작. 가상머신 os는 자기가 가상머신인줄 모름. 따라서 VM의 os는 기존의 os를 사용한다.
- 반가상화 : VM의 OS가 자기가 가상머신인걸 인지한다. 하드웨어와 직접 통신이 가능하다. VMM이 통역사가 아니라 리소스 관리만 하게 된다.
- 반가상화가 성능이 더 좋지만 OS를 수정해야되고 복잡도가 올라간다. 최근에는 전가상화가 선호된다.
VMWare : Type2 소프트웨어인데 인기가 좋다.
KVM : AWS에서 자주 쓰이는 Type1 소프트웨어. AWS에 100대의 컴퓨터를 10000명의 사용자가 쓰려면 10000개의 가상머신을 띄우게 된다.
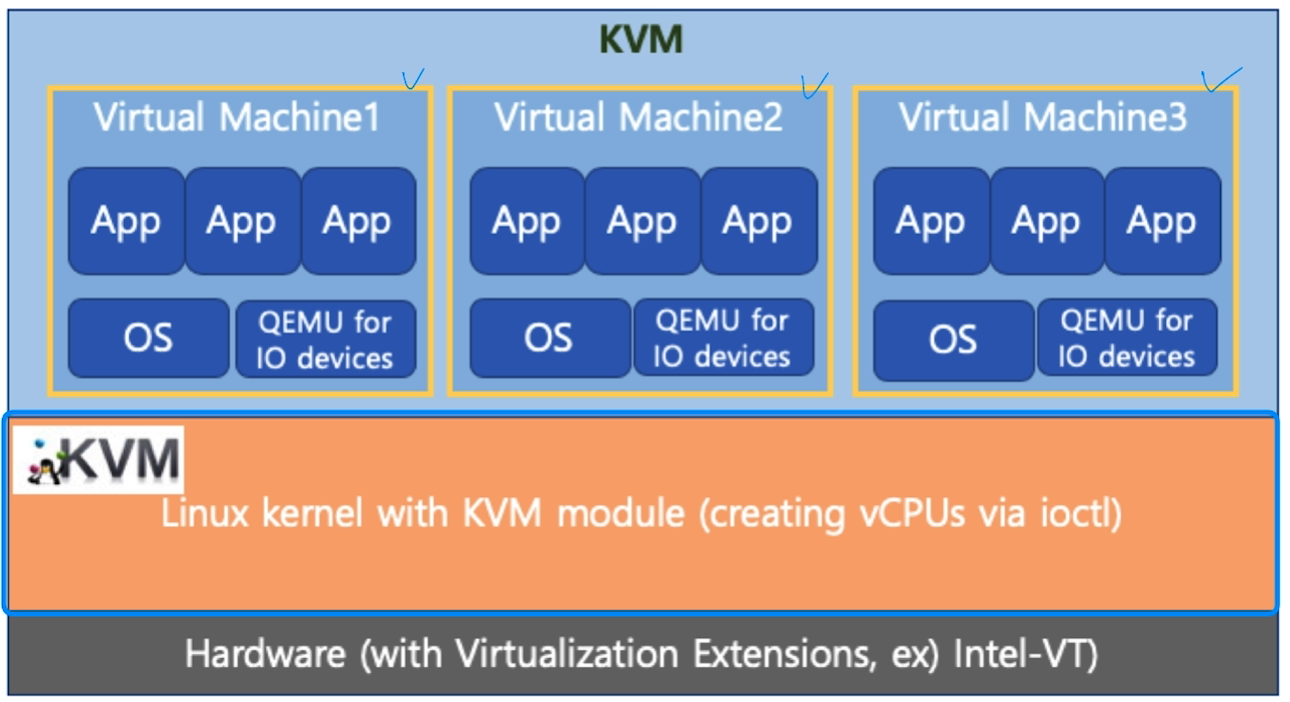
- 리눅스커널에서 ioctl이라는 명령어로 하드웨어에 직접 명령어를 내린다. 그래서 가상 cpu, 즉 vCPU를 만들 수 있다.
# Docker
- 가상 머신은 HW를 가상화 했다.
- Docker는 커널을 추상화 한다.
- 리눅스를 처음 설치했을때와 유사한 실행환경을 만들어 주는 리눅스 컨테이너 기술 기반
- 경량 이미지로 실행 환경을 통째로 백업, 실행 가능
# Java Virtual Machine
- 가상 머신과 달리 응용 프로그램 레벨에서 가상화 한다.
- 자바 컴파일러는 cpu dependency 가 없는 bytecode를 만든다.
- JVM은 이 바이트 코드를 각 운영체제에 맞게 해준다.
# Linux
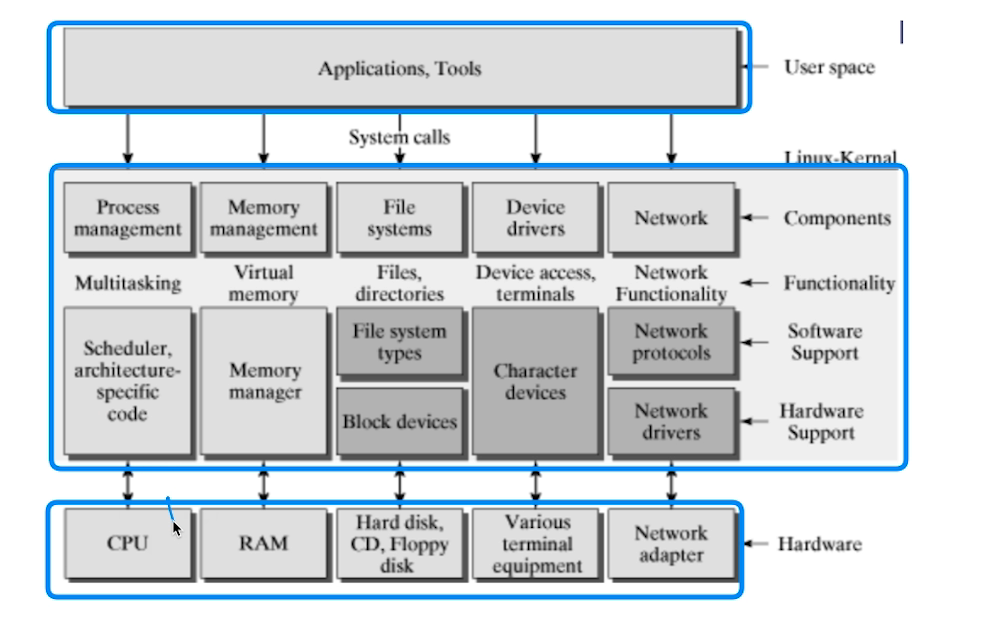
- shell : 사용자의 명령을 해석해서 커널에 명령을 요청해주는 역할.
- Bourne-Again Shell(bash) : 리눅스의 디폴트
- Bourne Shell : sh
- C Shell : csh
- Korn Shell : ksh 유닉스에서 많이 사용됨
- process management
- 멀티 프로세싱
- 스케쥴러
- memory management :
- 가상메모리 : page기반 메모리 관리
- IO device management :
- virtual file system을 통해 외부장치를 관리한다.
# Android
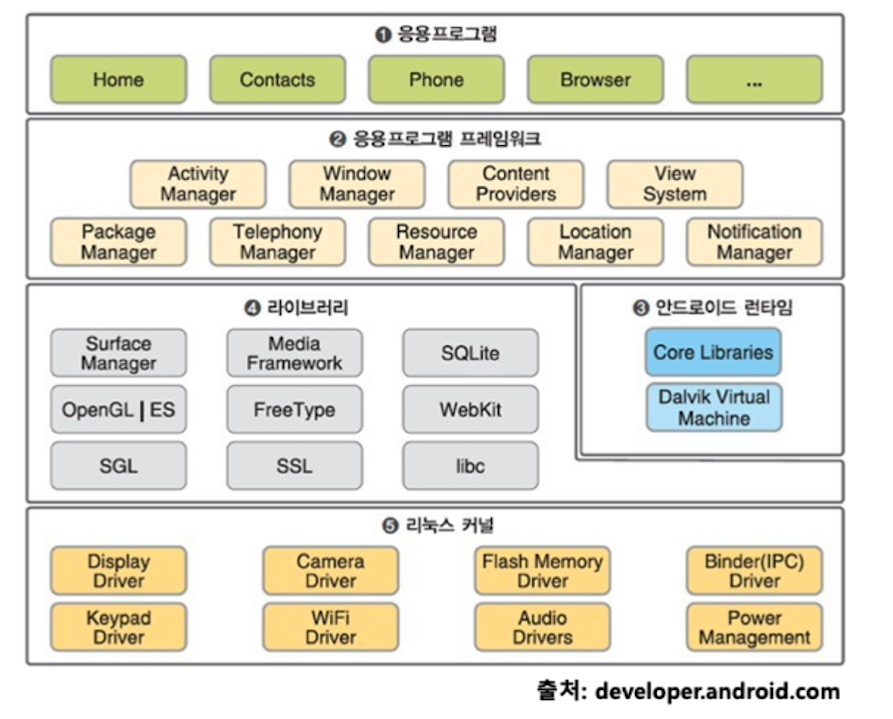
- 리눅스 기반
- 자바를 쓰기 때문에 JVM이 필요하다 = 런타임
- 2번과 3번을 합쳐서 안드로이드라고 볼 수 있다.
- OS는 리눅스OS에 안드로이드 플랫폼을 합친것이 안드로이드 스마트폰이라고 할 수 있다.
# IOT
- 초소형이며 기능 최소화
- 멀티태스킹, 보호모드, 커널모드, 가상메모리, 파일시스템 모두 없을 수 있다.